Metoda 4M (Bayes) – 4M-BASE-vmax « « (Update: 27-05-2026 00:33)
4M-BASE-vmax – wersja MAX!
Procentowości podwidm mössbauerowskich chondrytów zwyczajnych.
Wykresy (statystyki) (v.08-2023#230 - xxx%) (v.05-2026#299 - xxx%):
-
trójkątny (ternary plot);
-
gęstości prawdopodobieństwa (probability density function) i pudełkowy z wąsami (box and whisker);
-
składowych głównych (Principal Component Analysis, PCA);
-
BASE points classification – k-medoids clustering;
-
BASE points classification – Bayes classification rule (pie);
-
BASE points classification – 4M method clustering (pie);
-
analiza aglomeracyjna (cluster analysis).
Legenda: Chondryty zwyczajne typu H (■), L (♦), LL (●) oraz wartości średnie i centroidy klastrów (+)
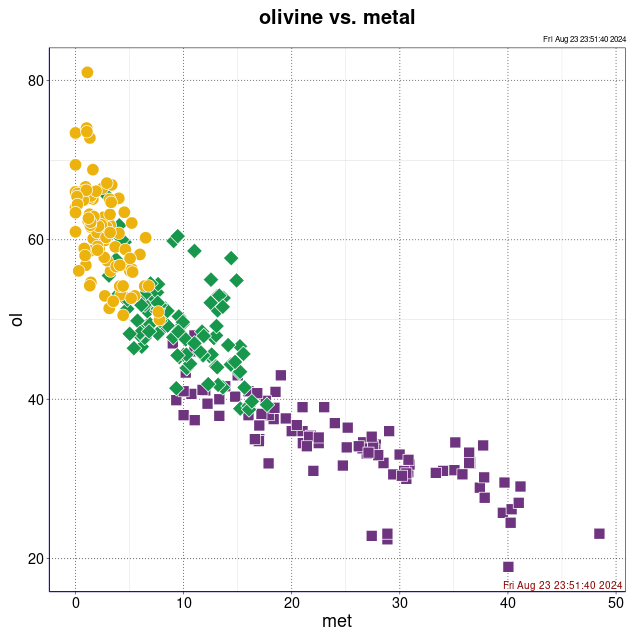
oliwin vs. metal (wykres sporządzony w pakiecie statystycznym R)
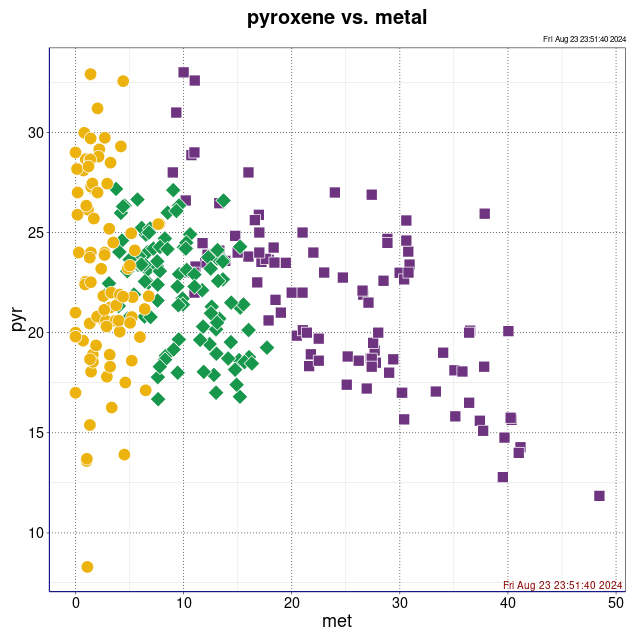
piroksen vs. metal (wykres sporządzony w pakiecie statystycznym R)
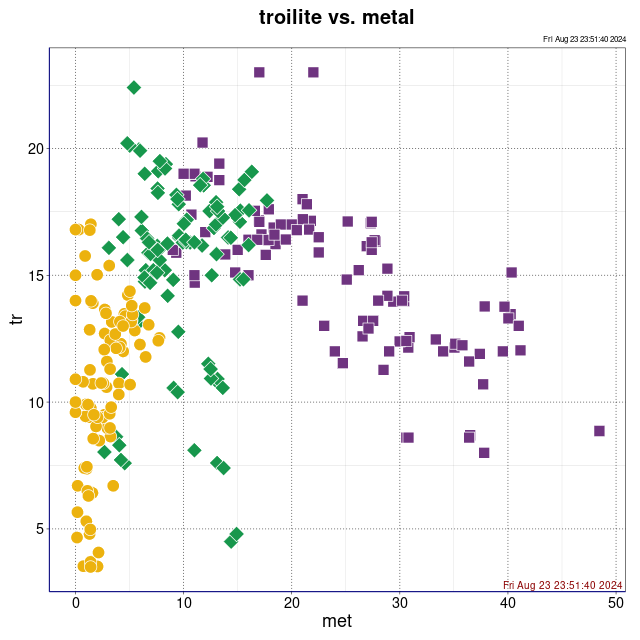
troilit vs. metal (wykres sporządzony w pakiecie statystycznym R)
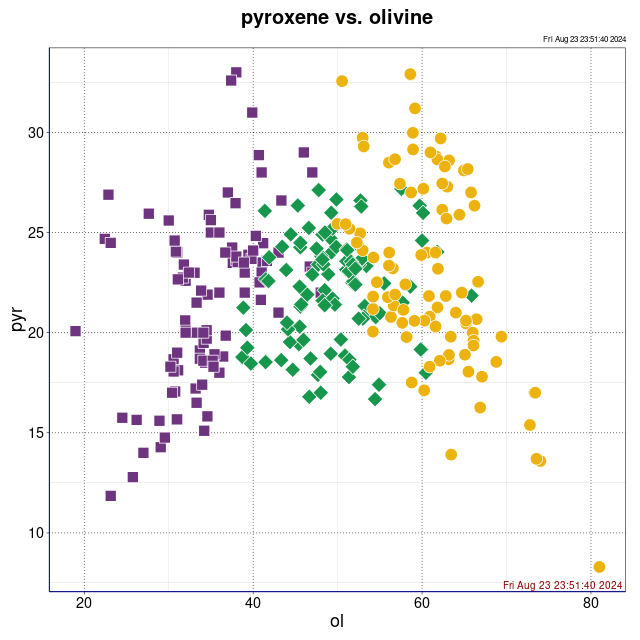
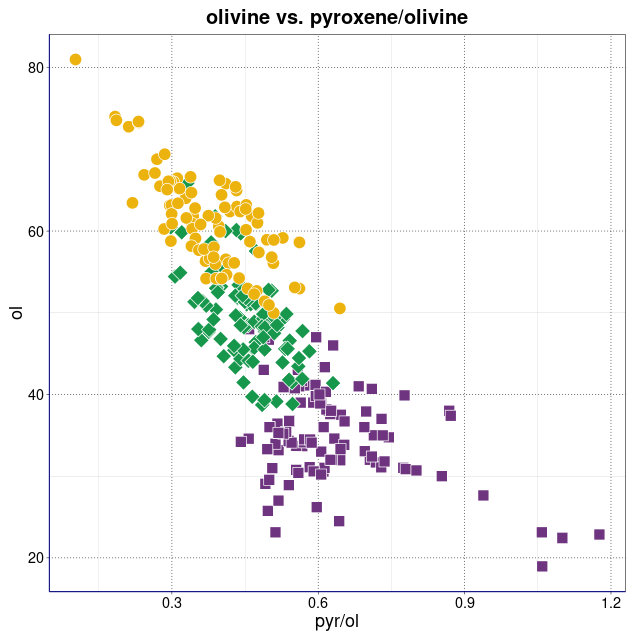
piroksen vs. oliwin (wykres sporządzony w pakiecie statystycznym R)
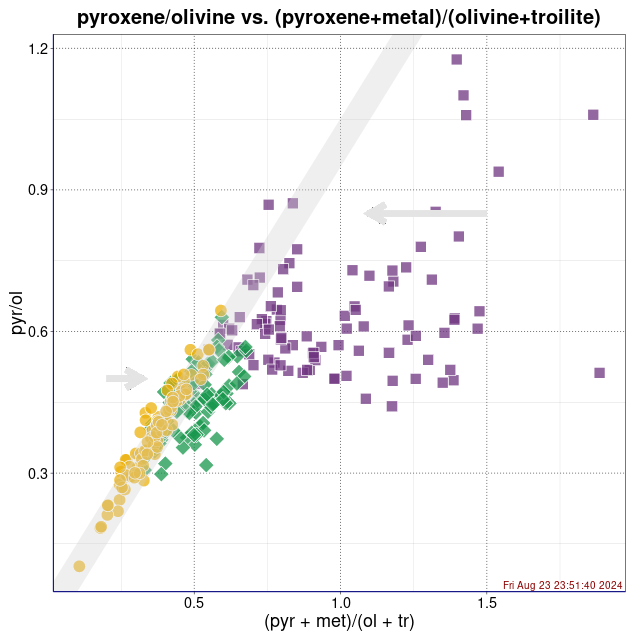
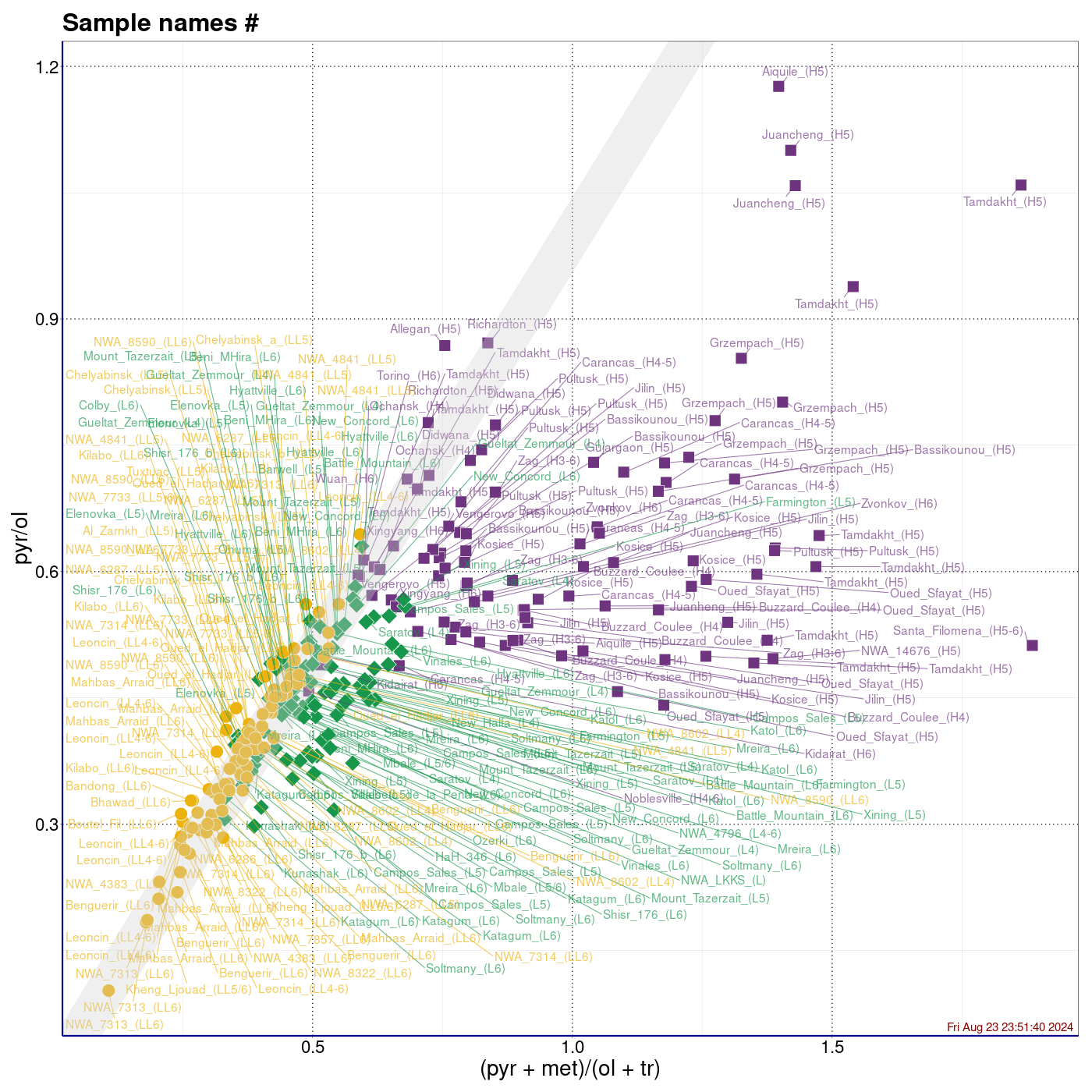
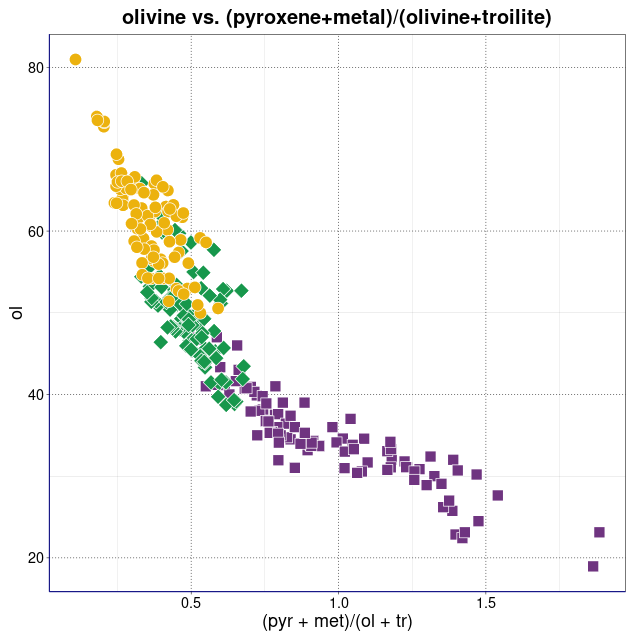
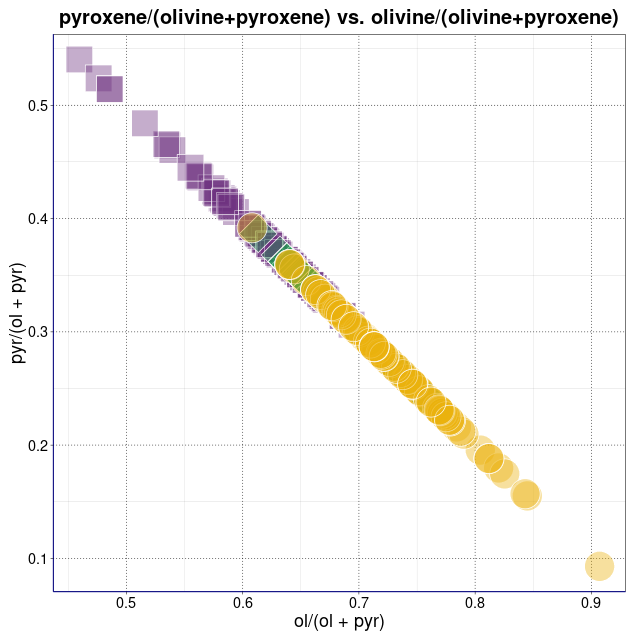
piroksen/oliwin vs. (piroksen+metal)/(oliwin+troilit) (wykres sporządzony w pakiecie statystycznym R)
 |
 |
 |
 |
 |
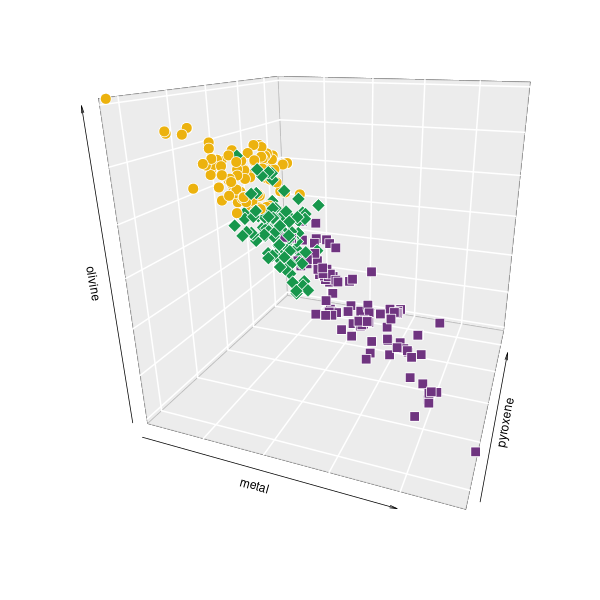 |
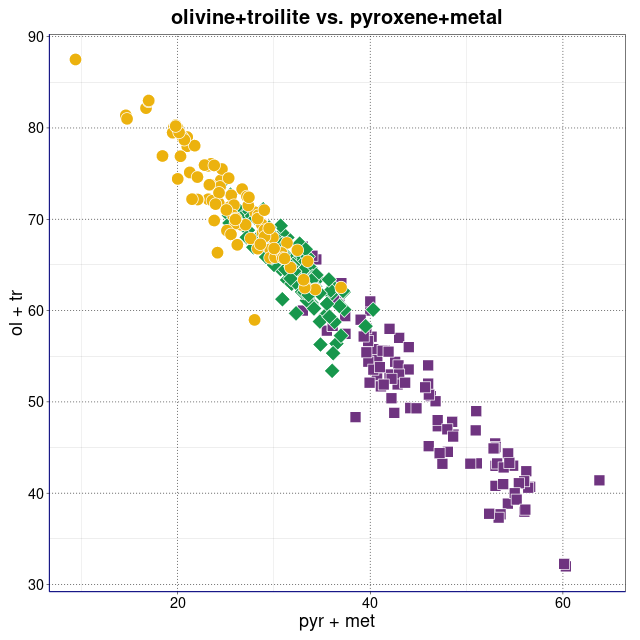
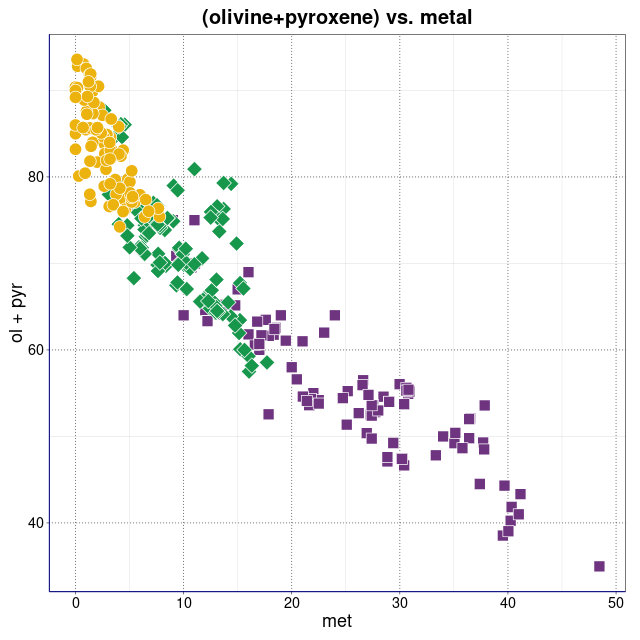
Varia. Kombinacje piroksen+metal/oliwin+troilit i inne (wykresy sporządzone w pakiecie statystycznym R)
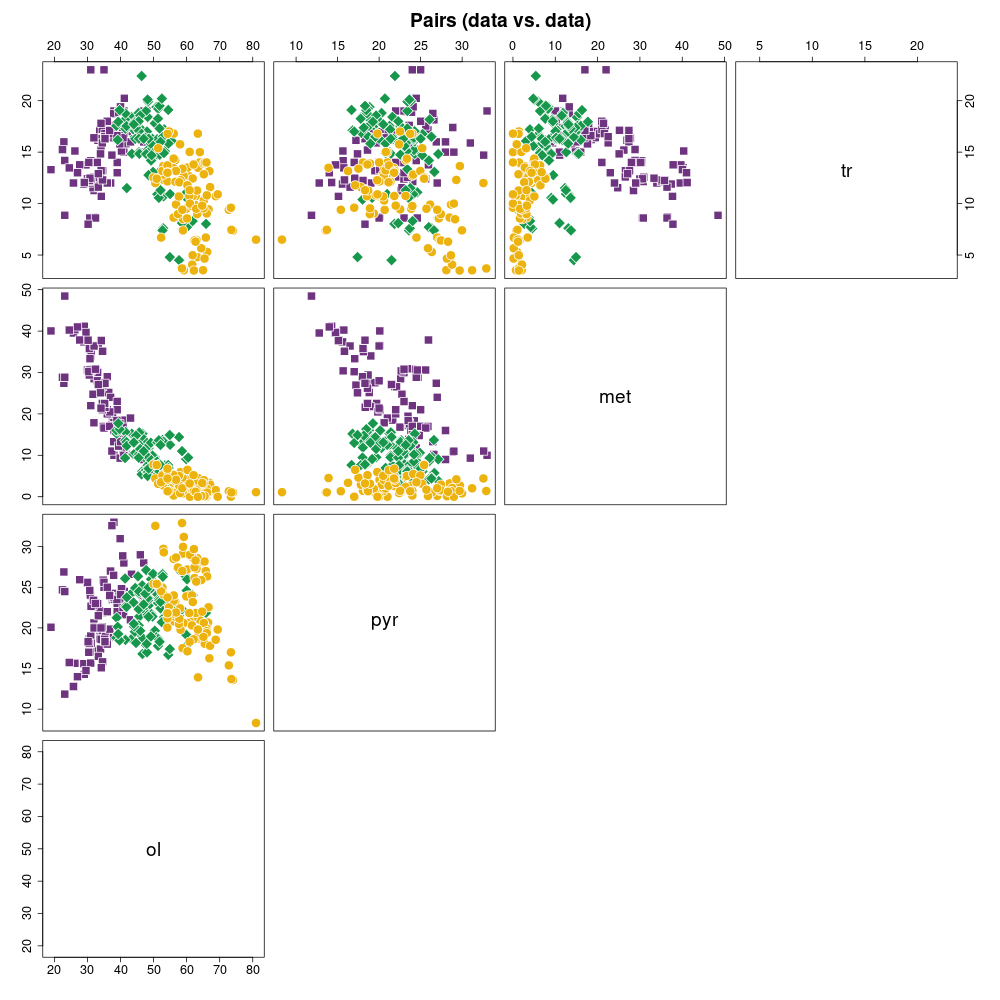
Wykres wszyscy-ze-wszystkimi (pairs)
(wykres sporządzony w pakiecie statystycznym R)
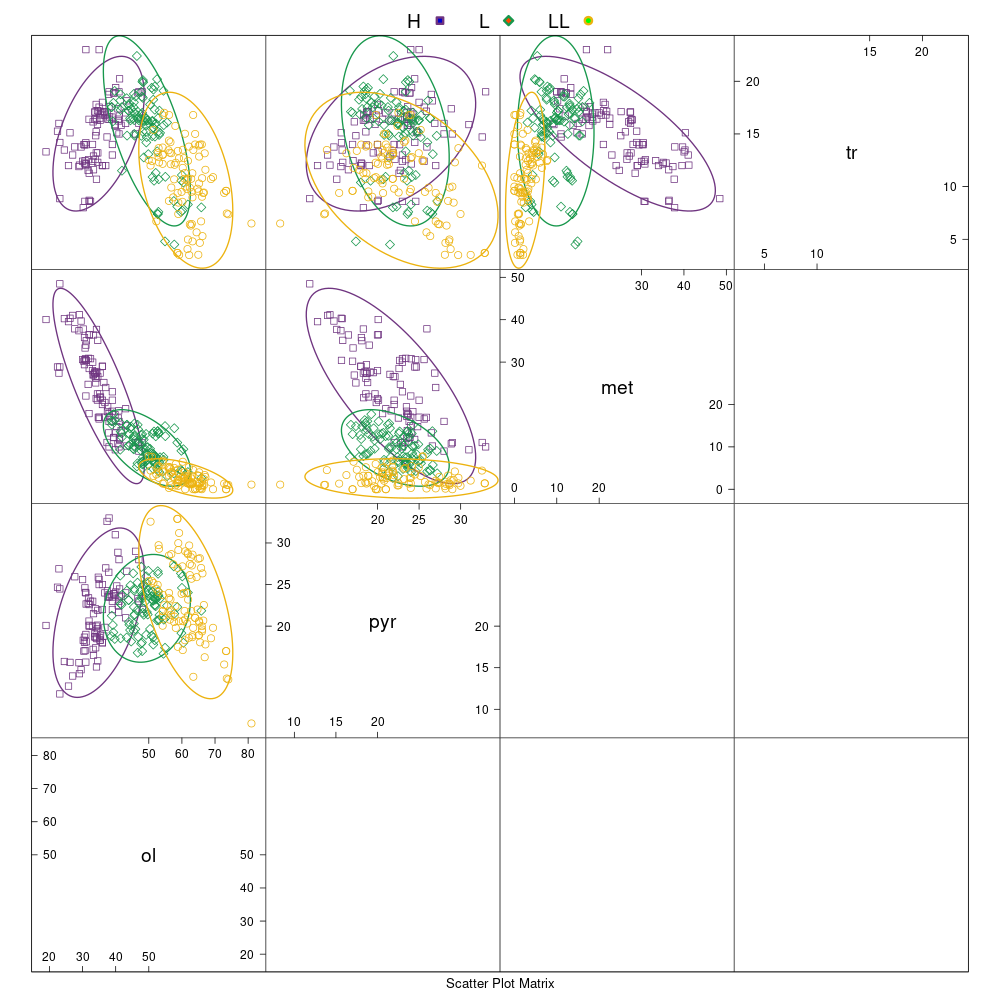
Wykres ellipse (wykres sporządzony w pakiecie statystycznym R)
(wielkość elips odpowiada poziomowi istotności 95% – 1,96σ)
Voronoi diagrams (4Mb BASE-vmax)
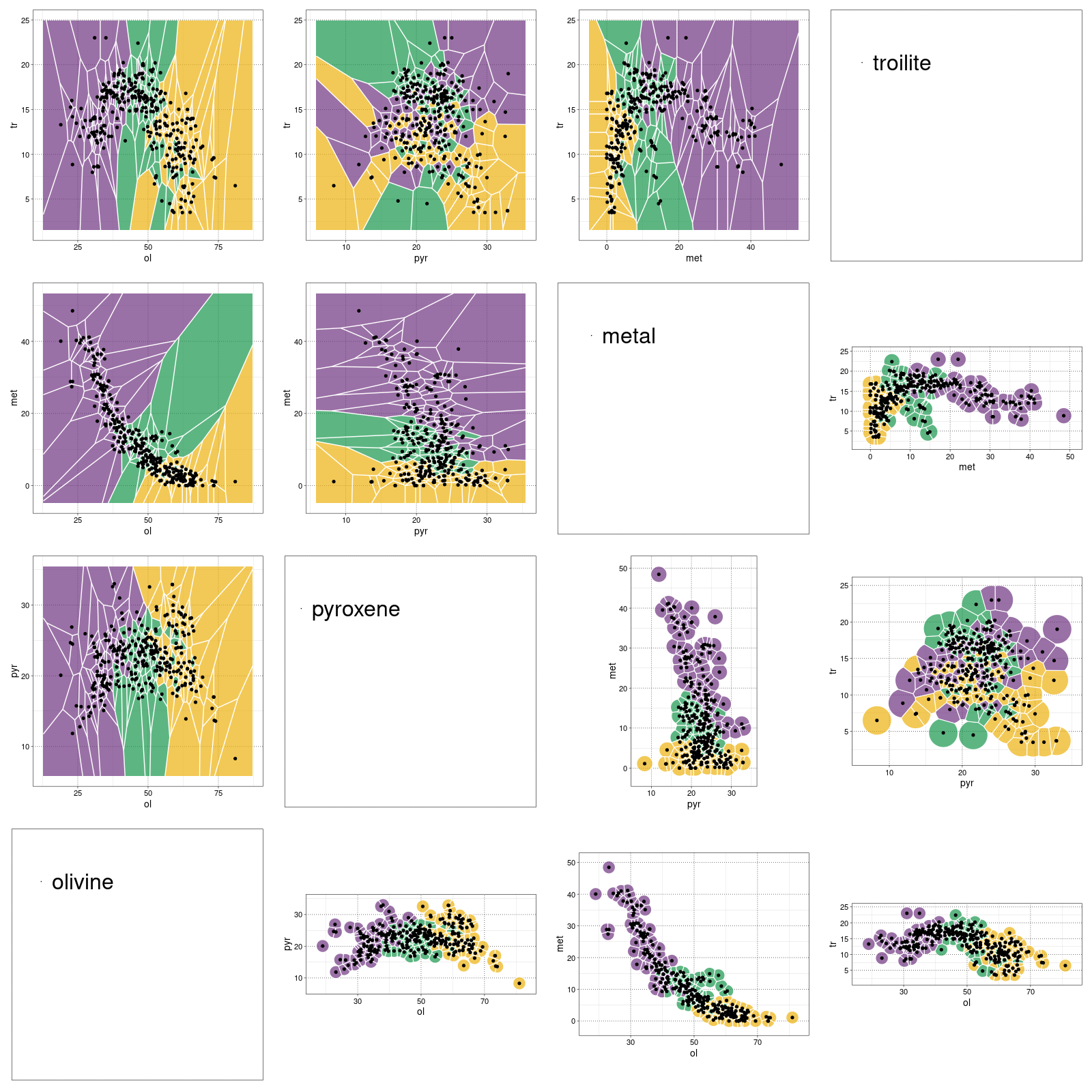
Voronoi diagram. Wykres zainspirowany opisywanymi w literaturze pomysłami prostego
podziału przestrzeni cech na rozłączne obszary zawierające meteoryty tylko jednego typu. Pierwotnie pomysł
zaproponował Verma et al., a nadal rozwija go Oshtrakh et al. (sources)
(wykres sporządzony w pakiecie statystycznym R)


Specjalnie dla naszych miłych Pań – "robak Woronoja" ![]() (BASE vmax (left), BASE v2n (right))
(BASE vmax (left), BASE v2n (right))
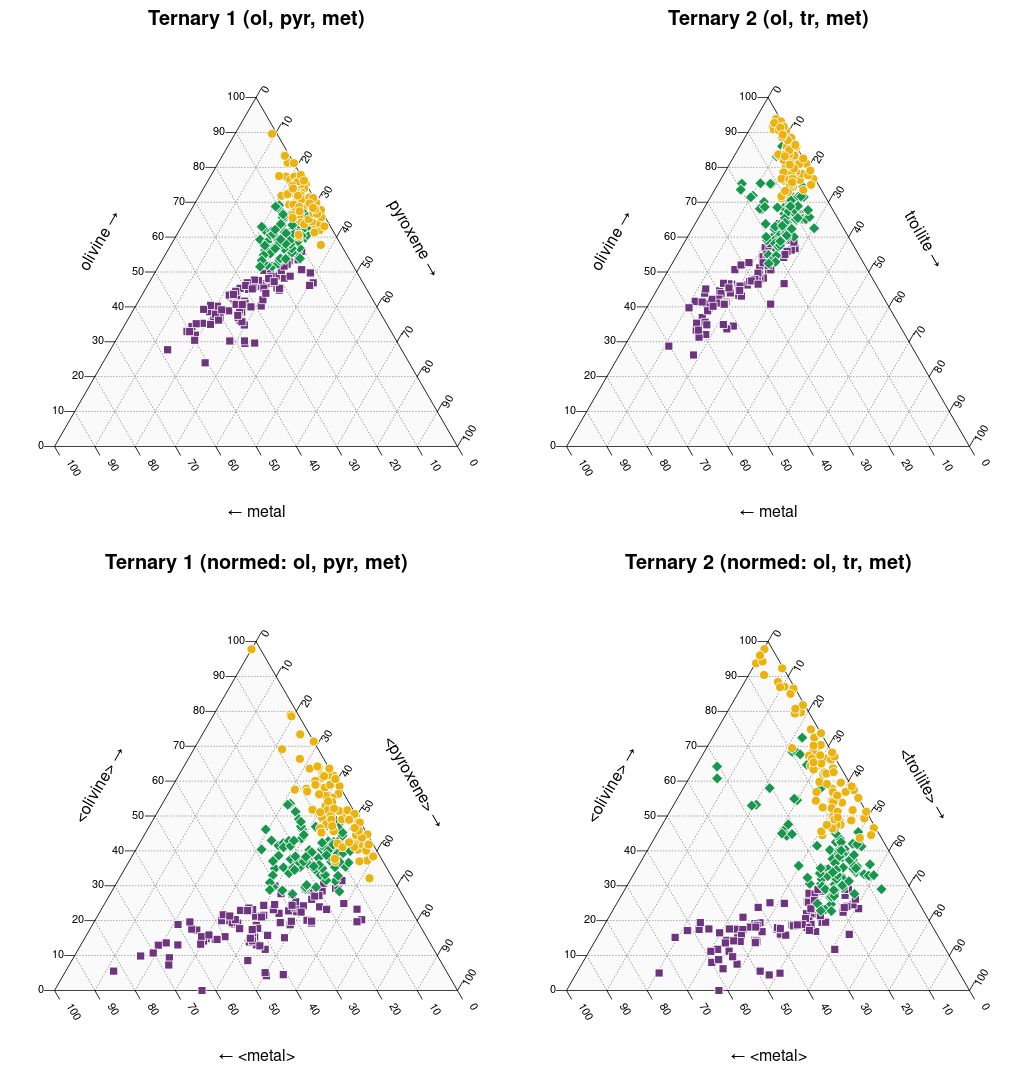
Wykres trójkątny (ternary plot) na którym doskonale widać potencjał
dyskryminacyjny parametrów mössbauerowskich
(wykres sporządzony w pakiecie statystycznym R)
Density, box and whisker (4Mb BASE-vmax)
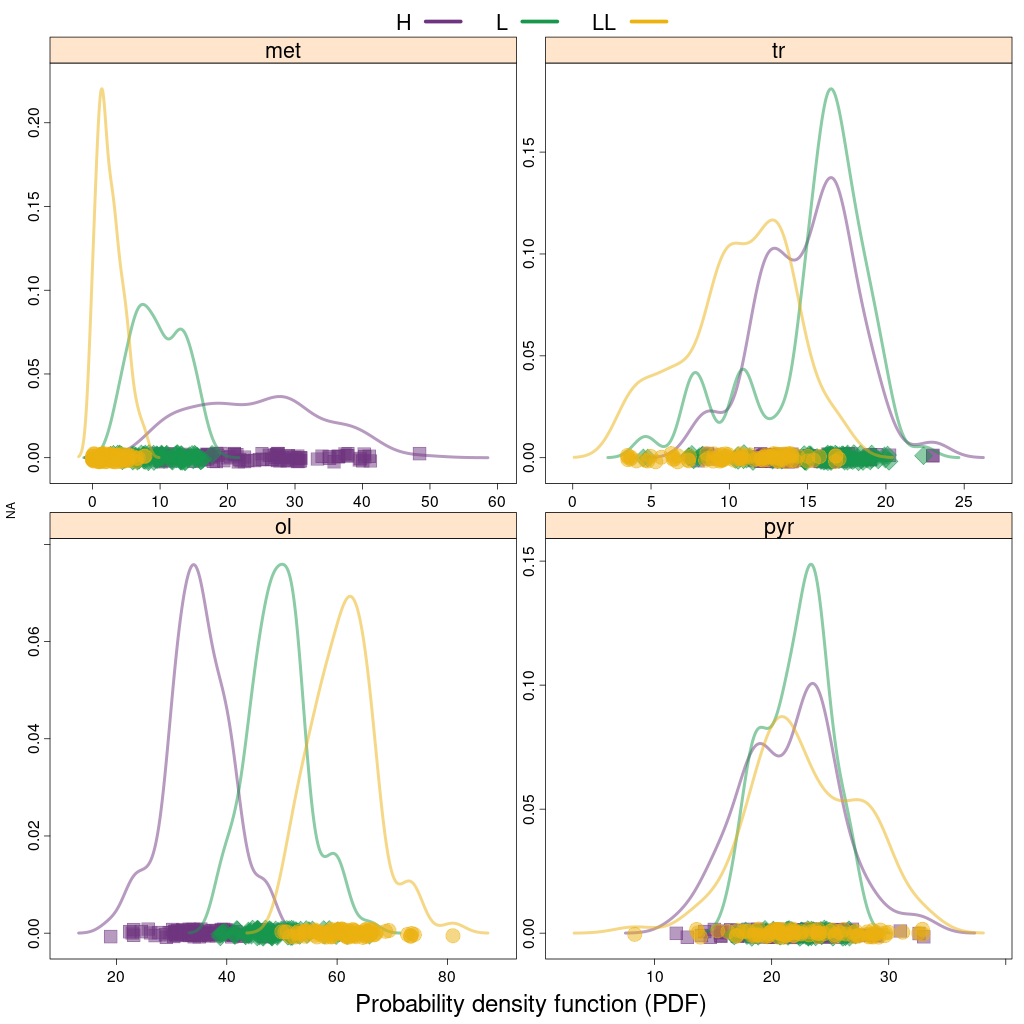
Wykresy density – wykresy oszacowania gęstości rozkład danych.
Podobnie jak histogram, podsumowuje się zależność między wartościami parametrów a liczbą obserwacji, ale zamiast częstotliwości
podsumowuje się ją jako ciągłą funkcję gęstości prawdopodobieństwa (probability density function, PDF). Jest
to prawdopodobieństwo, że dana obserwacja ma określoną wartość.
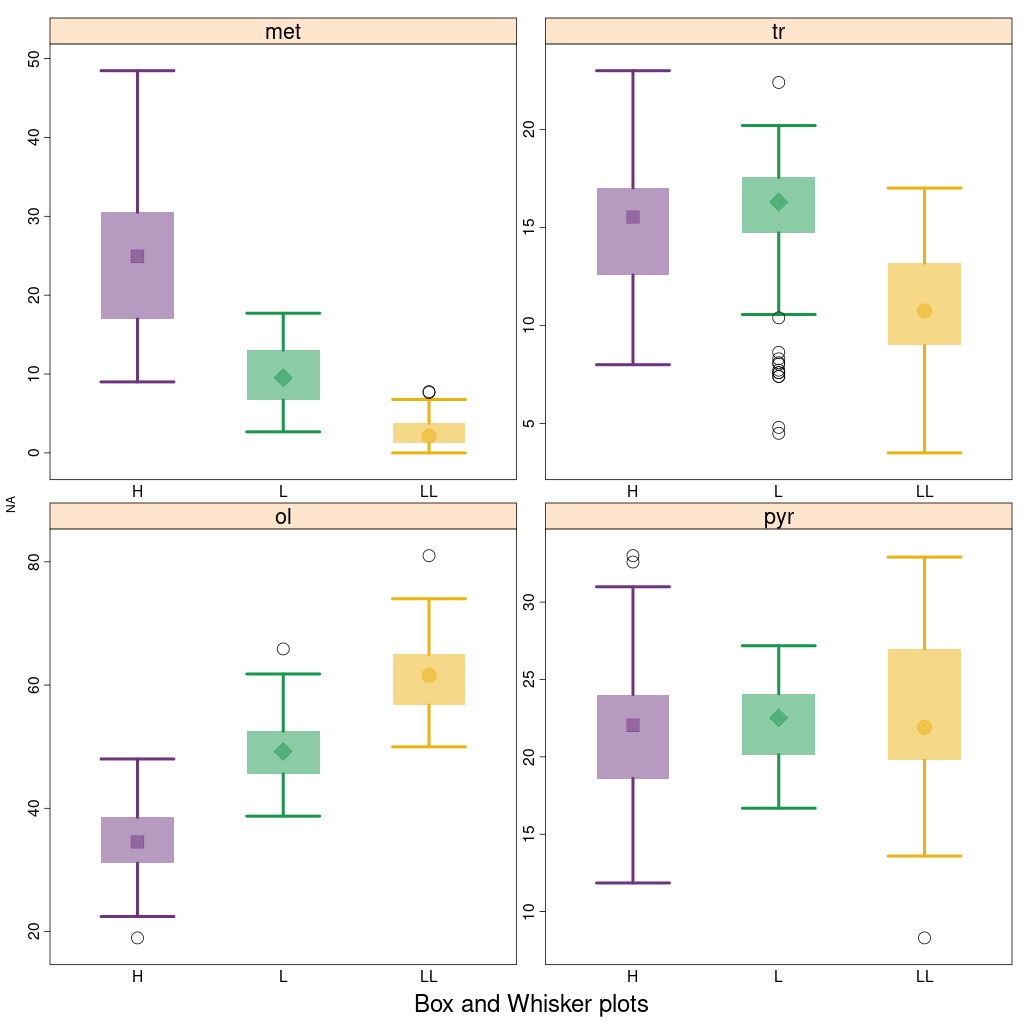
Wykresy box and whisker – wykresy pudełkowe i wąsy podsumowują rozkład danego parametru; pokazują ramkę
dla 1 i 3 kwartyla, linię w ramce (?!) dla 50. centyla (medianę) i kropkę dla średniej. Wąsy pokazują 1,5 × wysokość
prostokąta (zwanego przedziałem między kwartylami, interquartile range, IQR), co wskazuje oczekiwany zakres
danych, a wszelkie dane poza tymi wąsami są uznawane za wartości odstające i oznaczone kropką.
(wykres sporządzony w pakiecie statystycznym R)
PCA – Principal Component Analysis (4Mb BASE-vmax)
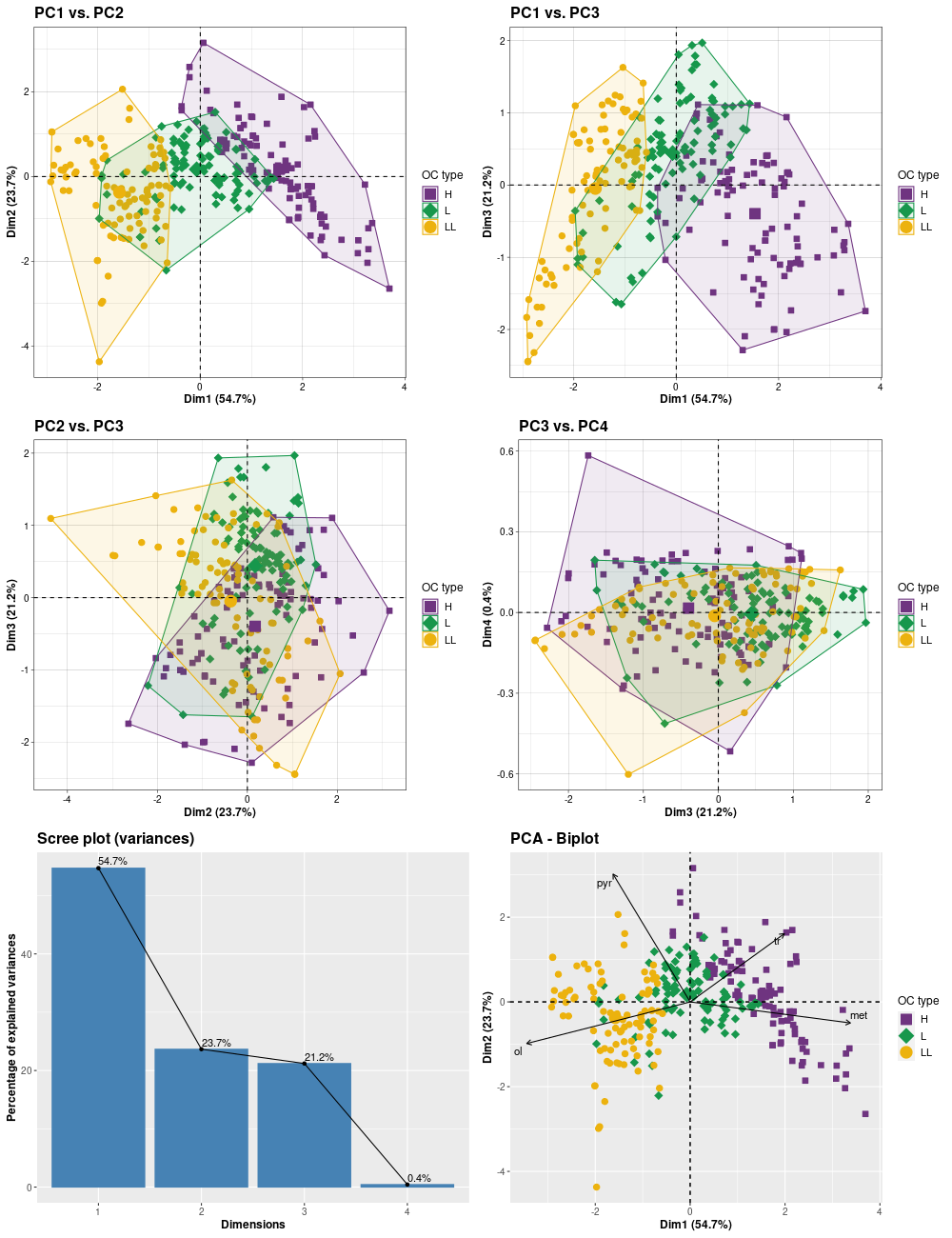
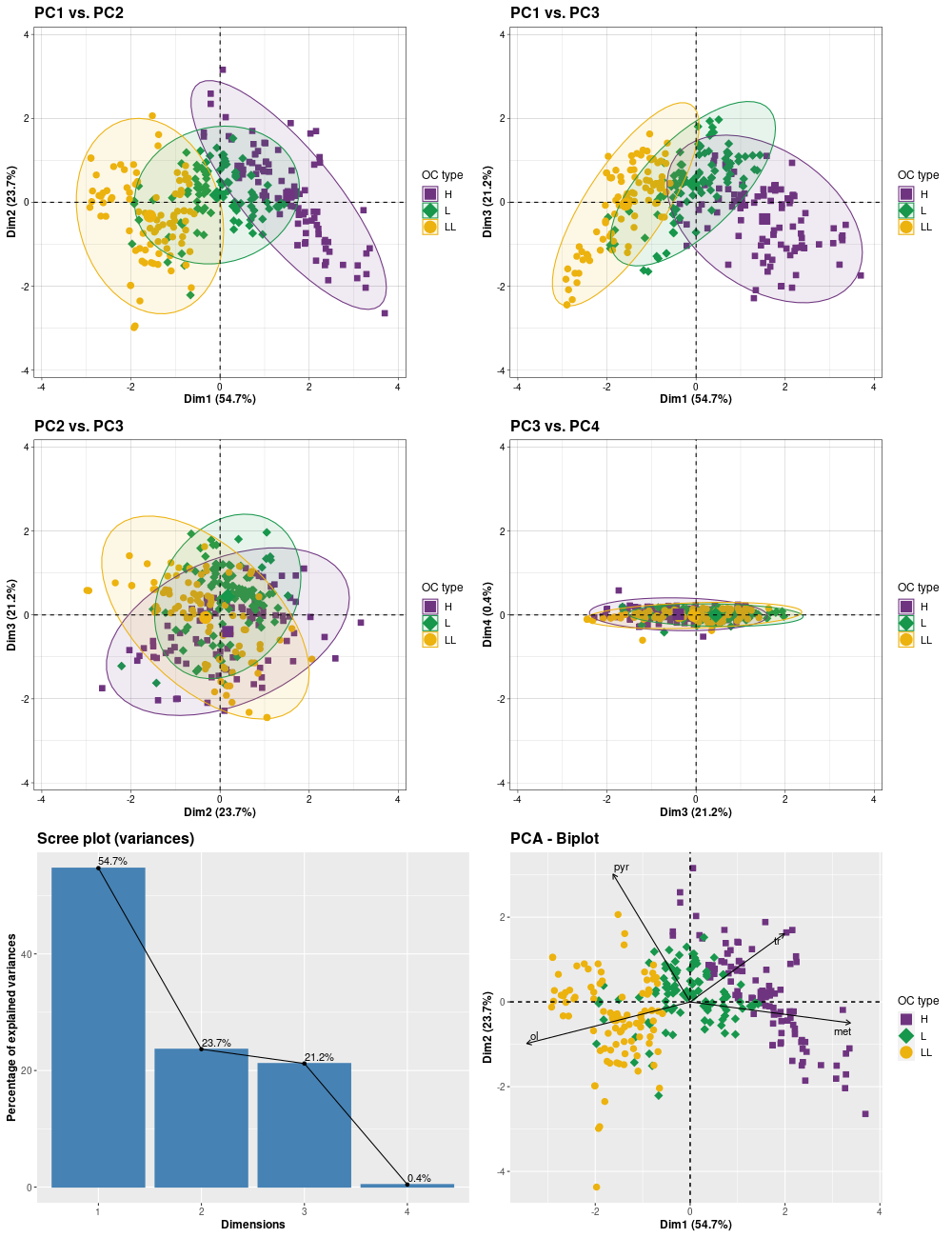
Principal Component Analysis (PCA)
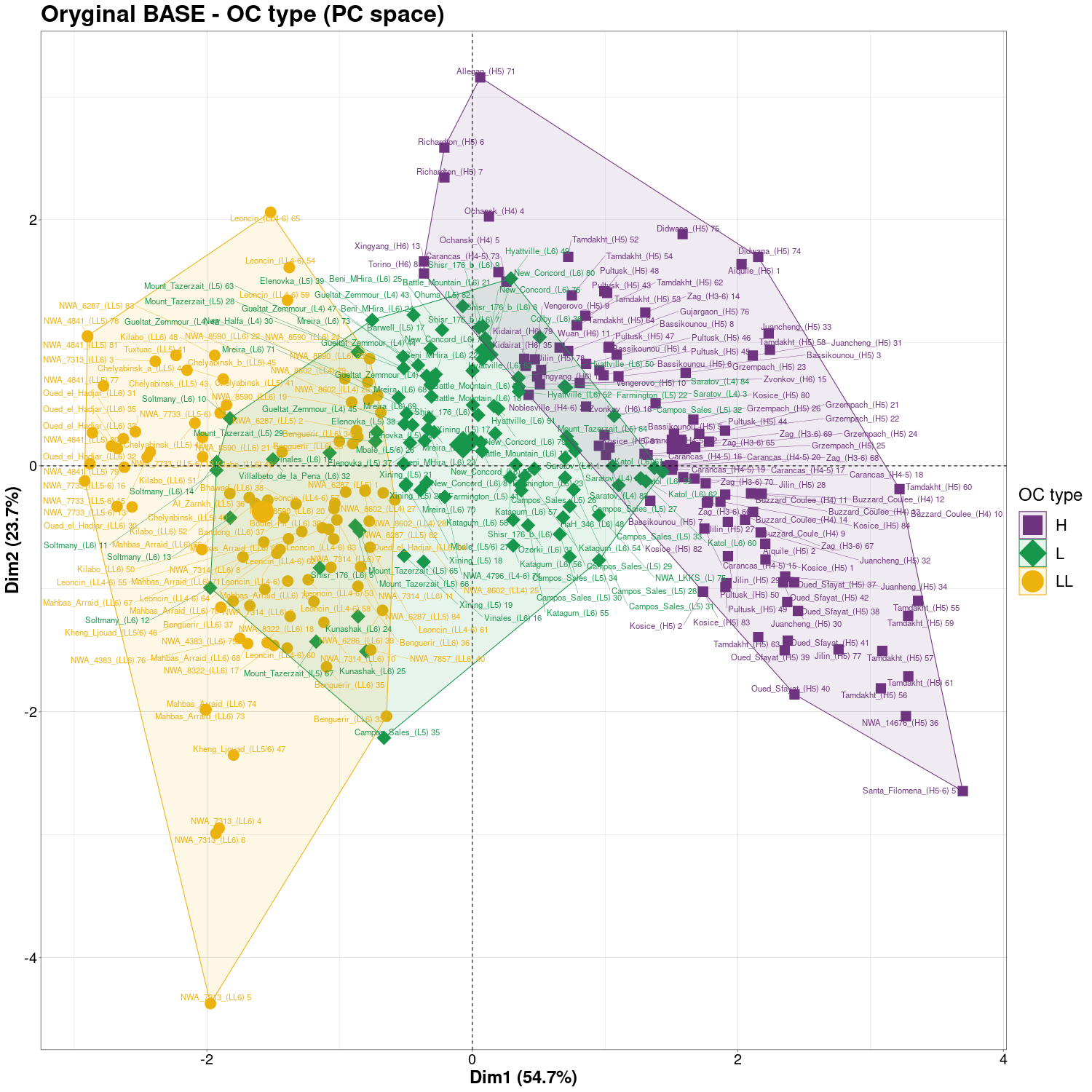
BASE points classification – k-medoids clustering (4Mb BASE-vmax)
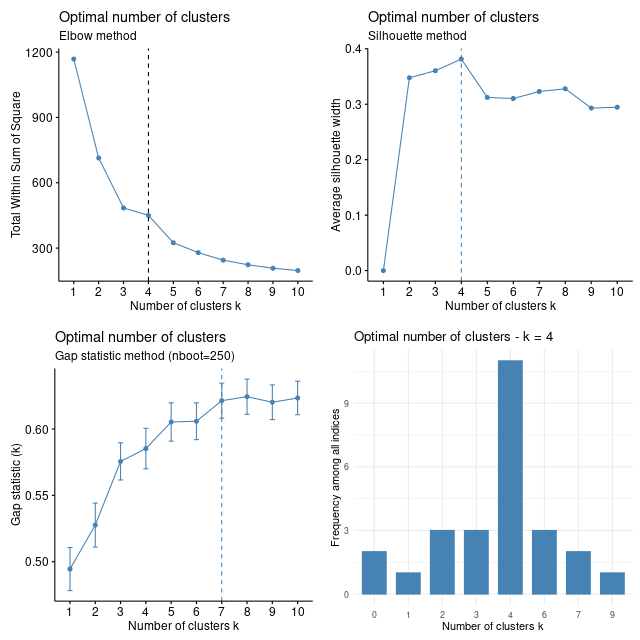
Optimal number of clusters
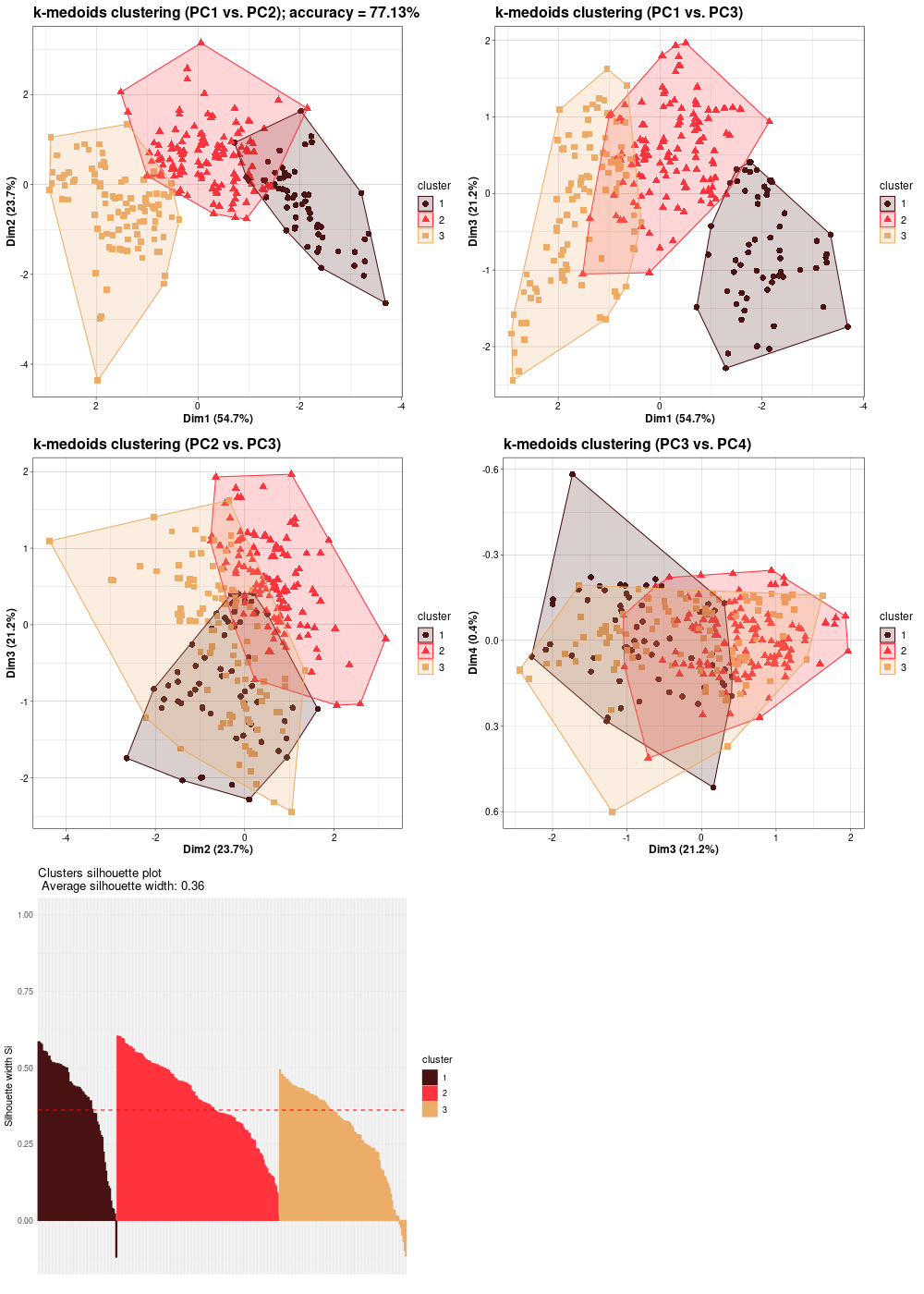
k-medoids clustering
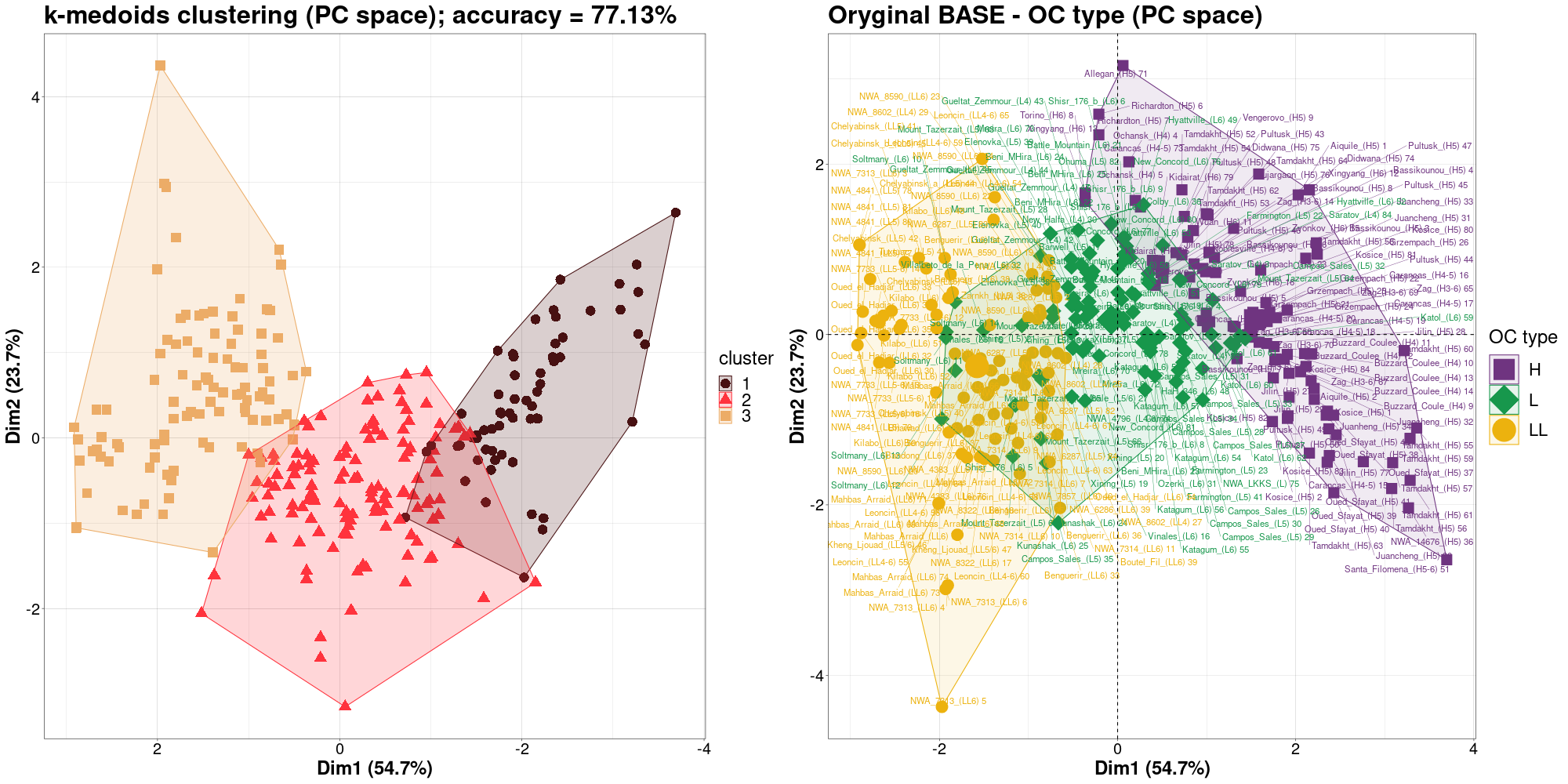
k-medoids clustering in PCA view (version
HiRes) |
{kind=link}
BASE points classification – Bayes classification rule (4Mb BASE-vmax)
Bayes classification rule (Jajuga 1993).
Obiekt xi należy do tej klasy j, dla której funkcja:
gj(xi) = –0.5 * dMj * dMj – 0.5 * ln(detSj) + ln(pj)
osiąga minimum po j (numer klasy).
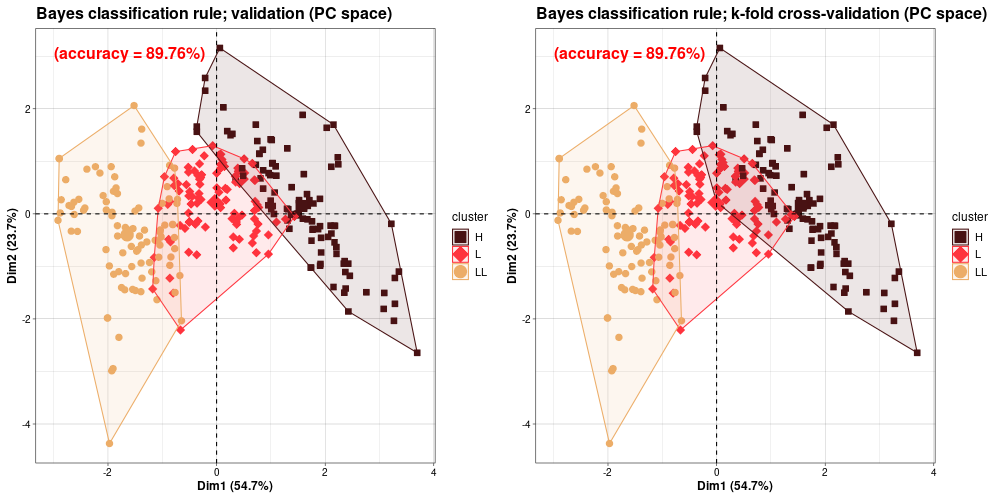
Bayes classification rule in PCA view (was:
accuracy = ???) ...compare 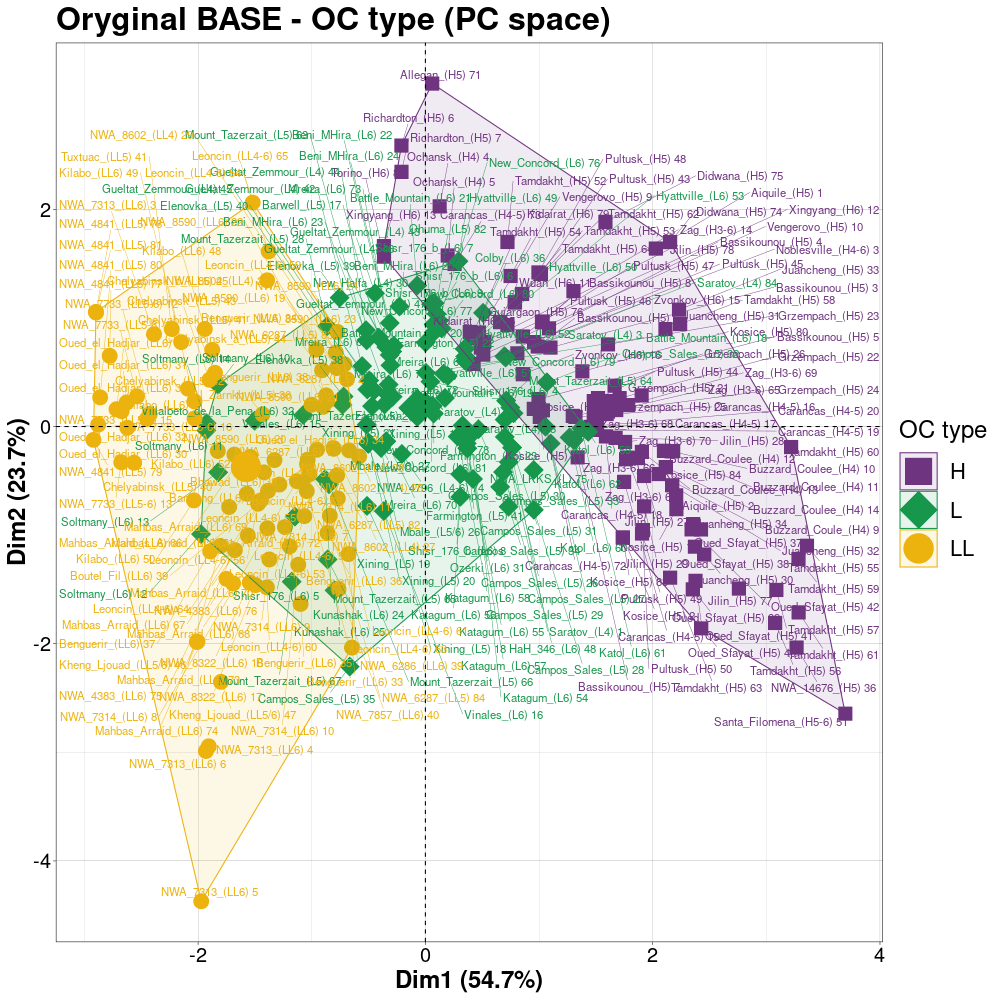 (version HiRes)
(version HiRes) |
 |
|
|
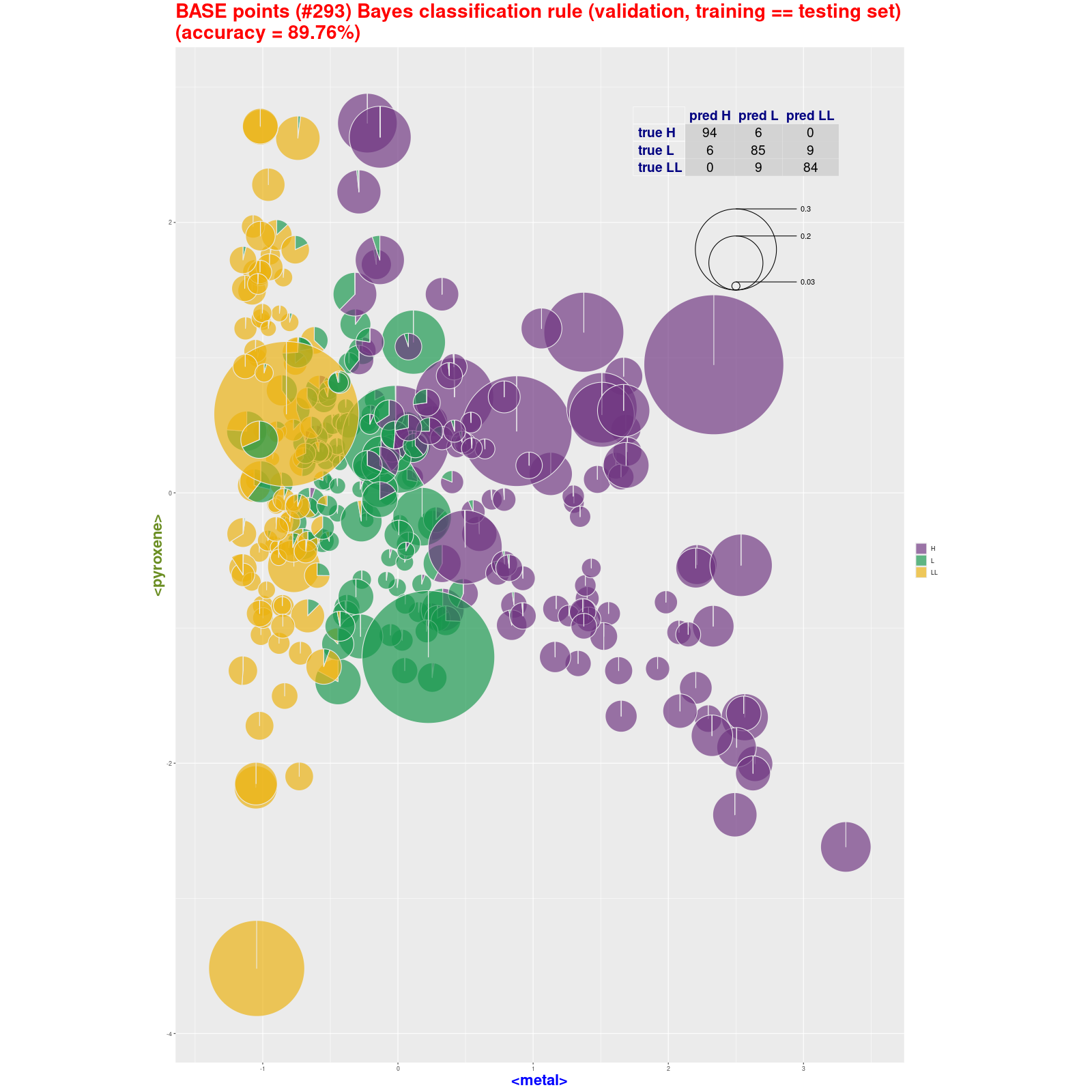
BASE points classification – Bayes classification rule (pie)
(validation, training ≡ testing set) Tabela z wynikami klasyfikacji.
|
|
 |
|
|
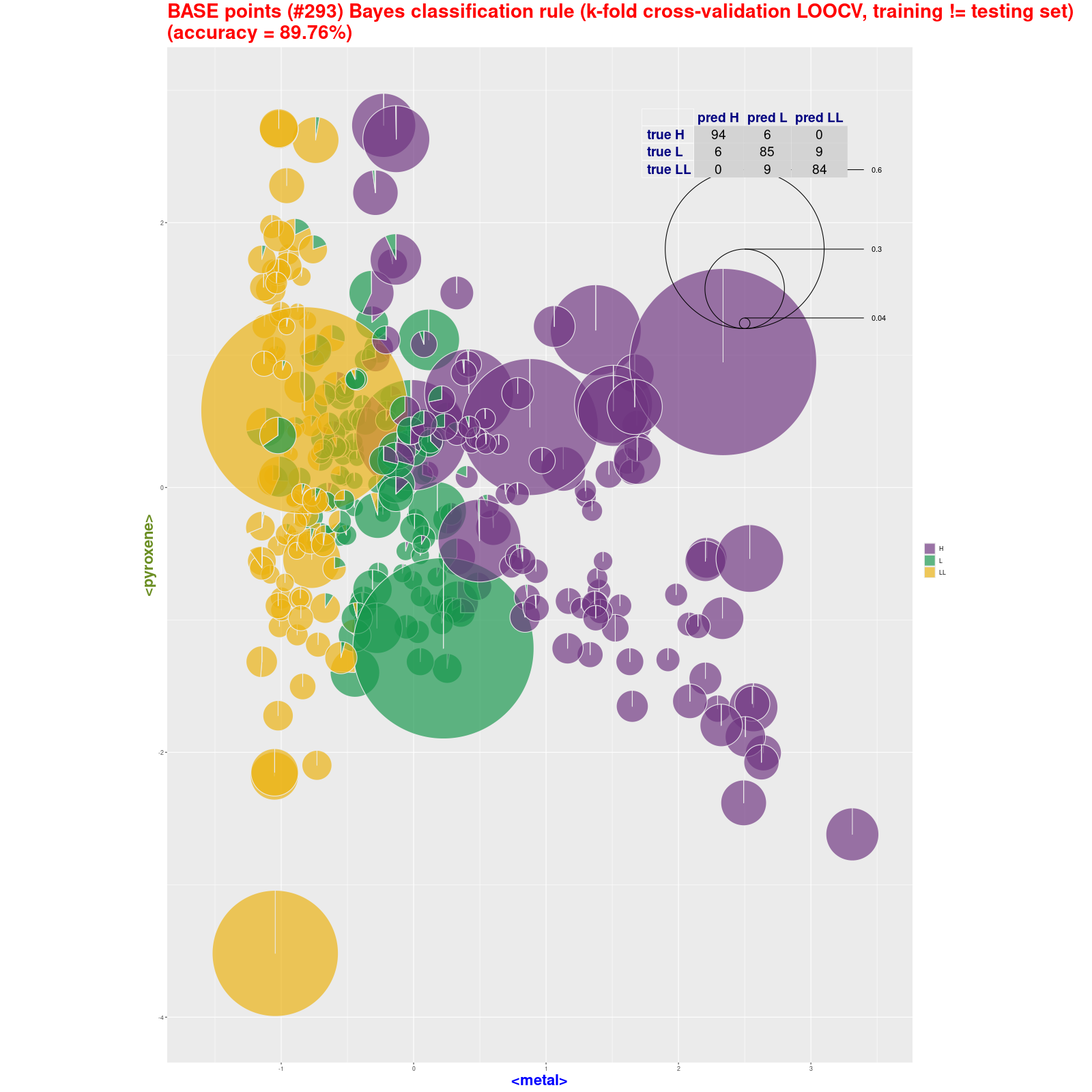
BASE points classification – Bayes classification rule (pie)
(k-fold cross-validation LOOCV, training ≠ testing set) |
|
BASE points classification – 4M method clustering (4Mb BASE-vmax)
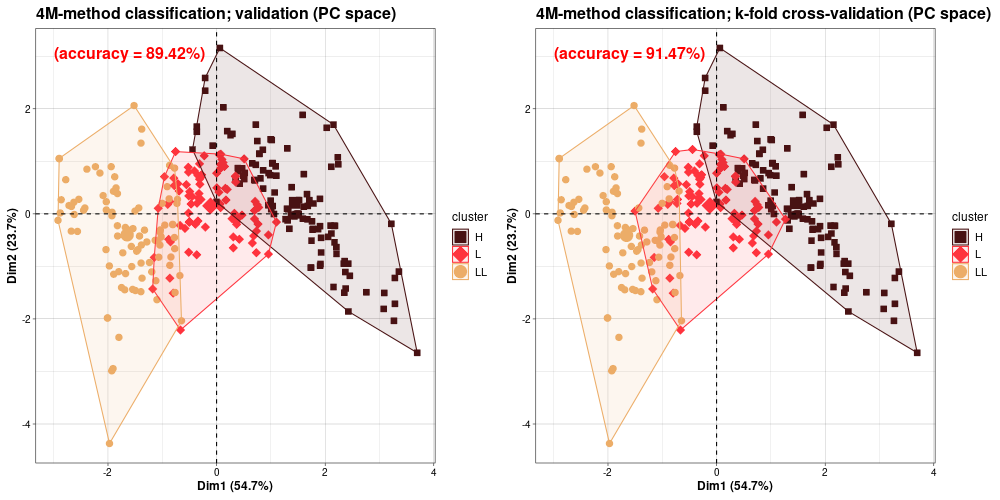
4M-method clustering in PCA view ...compare
(version HiRes) |
 |
|
|
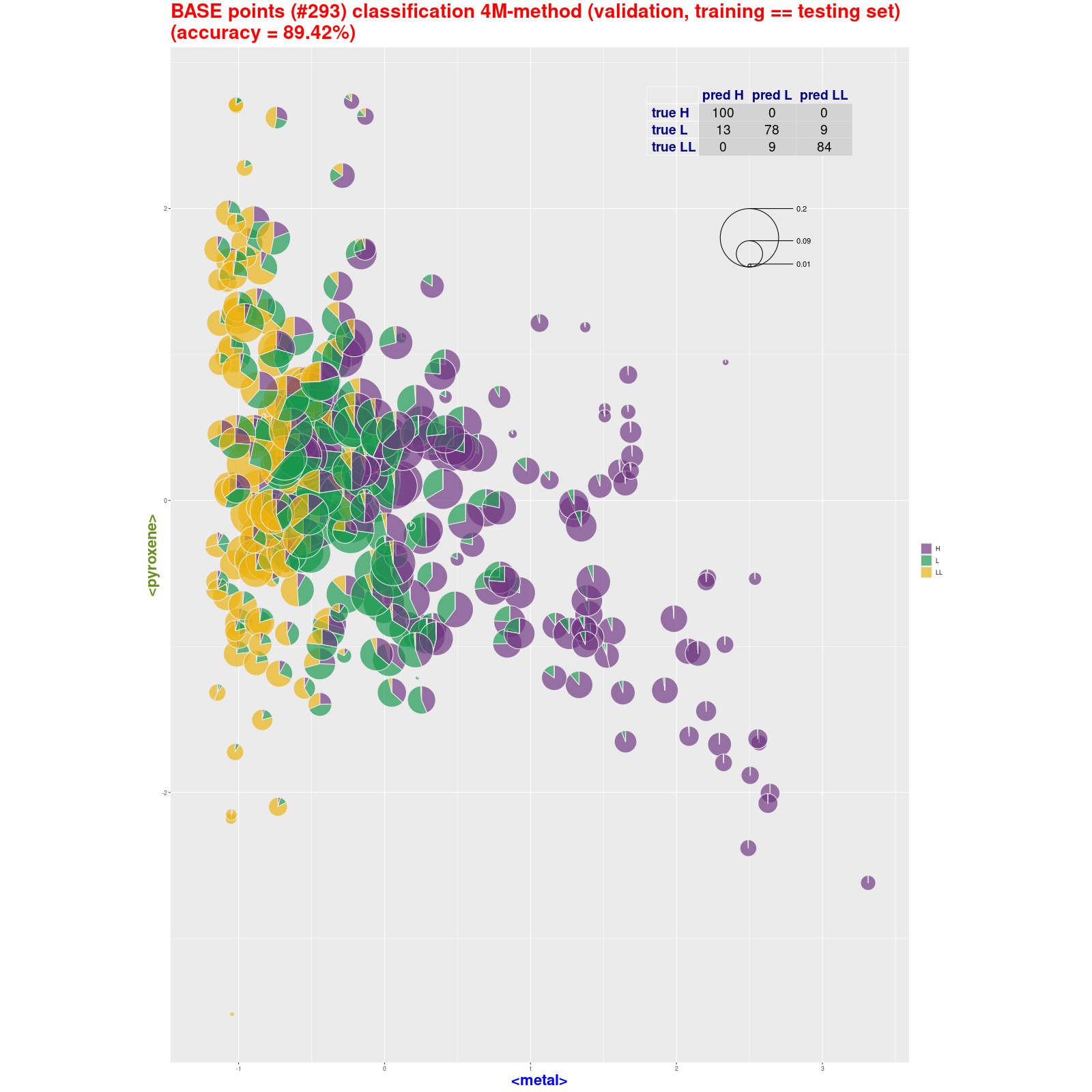
BASE points classification – 4M-method (pie) (validation,
training ≡ testing set) Tabela z wynikami klasyfikacji.
|
|
 |
Analizując trafność (accuracy) metody 4M warto porównać wyniki dla "chybionych" trafień z wynikami analizy skupień. Warto spojrzeć na drzewo klasyfikacyjne w metodzie Ward.D2. Jak część "chybionych" meteorytów jest podobna do nie swoich klas:
|
|
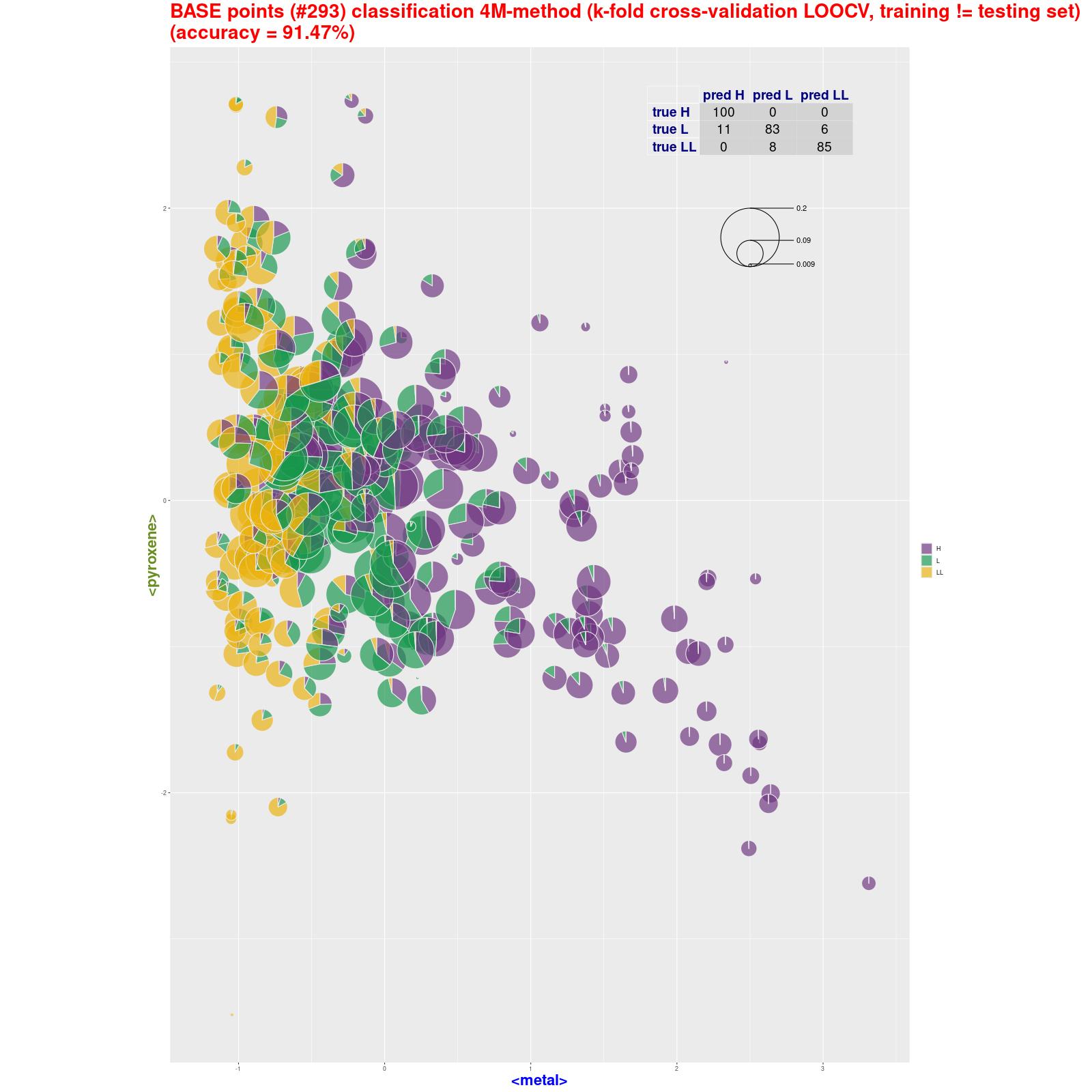
BASE points classification – 4M-method (pie) (k-fold
cross-validation LOOCV, training ≠ testing set) Tabela z wynikami klasyfikacji.
|
|
 |
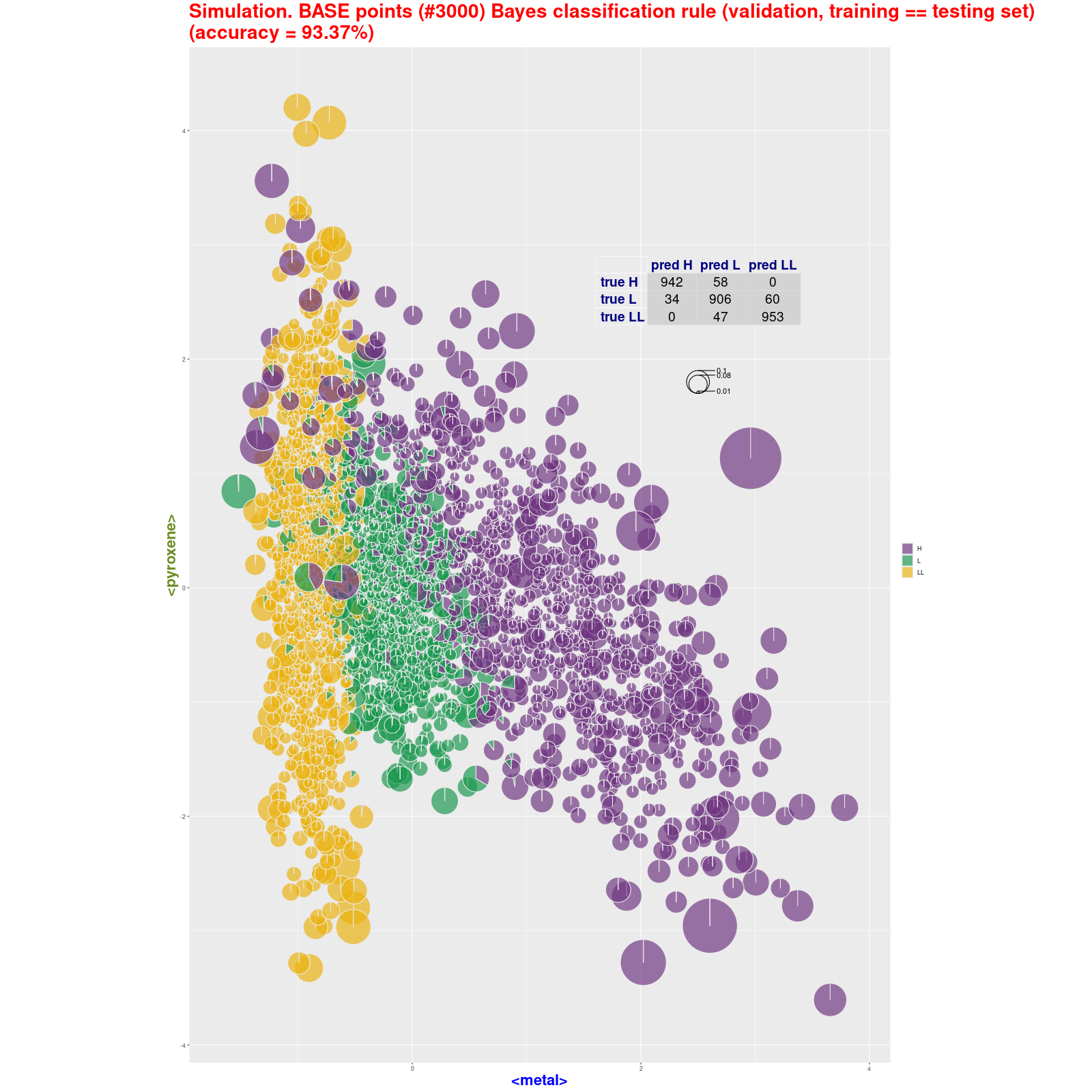 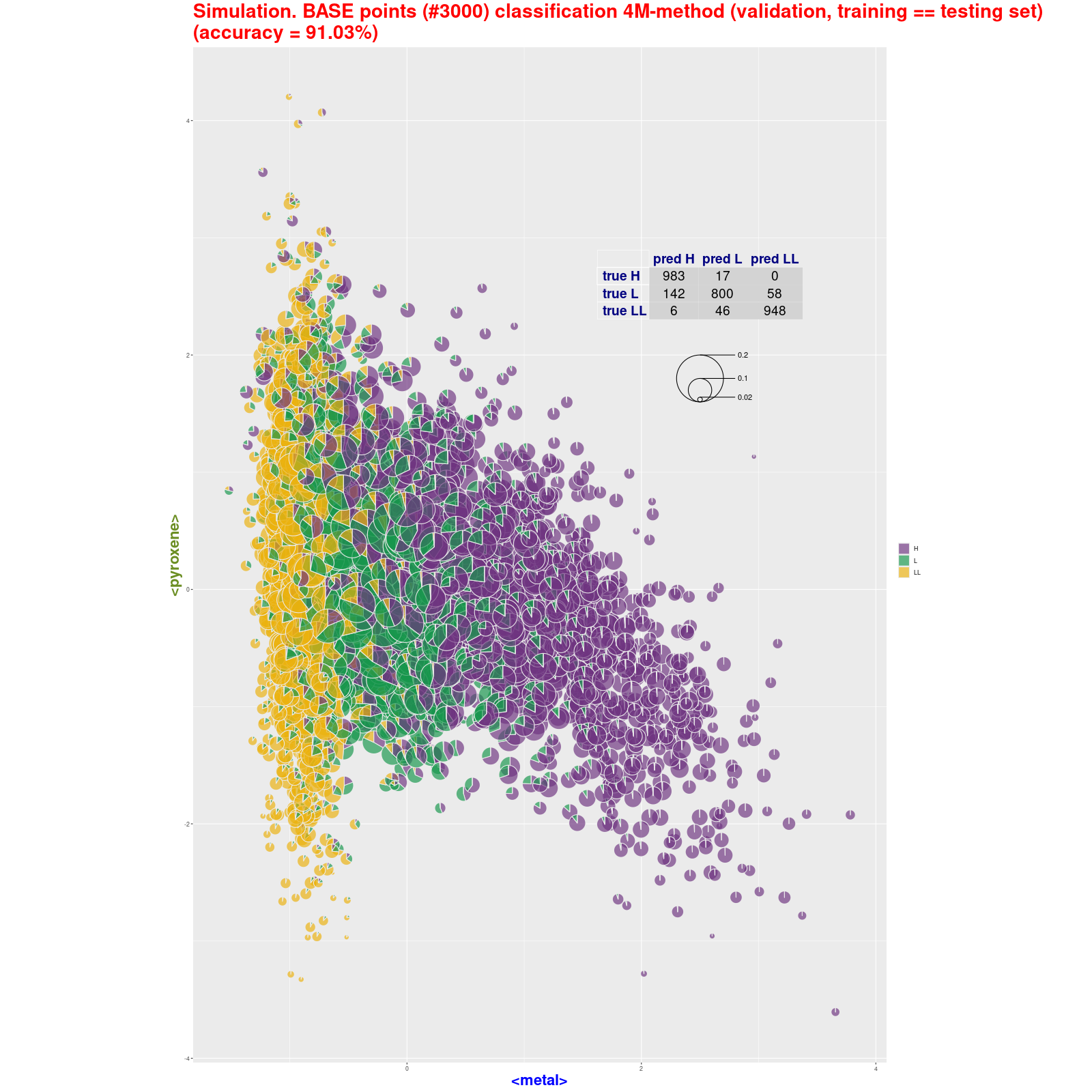 |
|
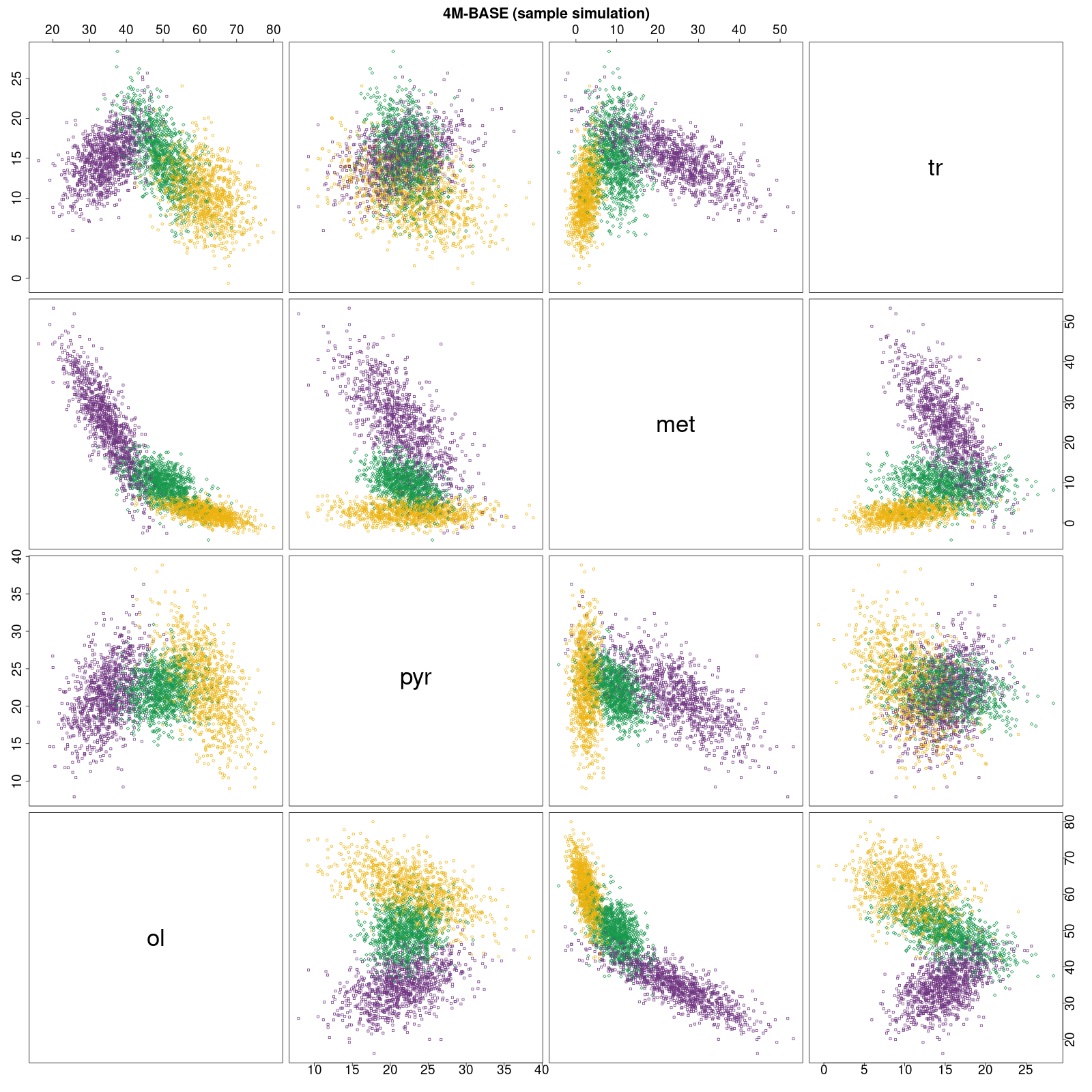
Symulacja BAZY dla 3×1000 próbek Symulacje testowych baz (losowe zbiory 1000 próbek dla każdego typu)
klasyfikowane metodą 4M dawały wynik trafności (accuracy) w przedziale 88-92%; klasyfikowane
Bayes classification rule dawały wynik trafności (accuracy) w przedziale >92% (91,43-93,13) Patrz → BASE point classification (pie): Bayes
classification rule • 4M method Tabele z wynikami klasyfikacji: Bayes classification rule • 4M method |
|
Cluster analysis (4Mb BASE-vmax)

complete |

Ward.D |

Ward.D2 |

single |

average (UPGMA) |

mcquitty (WPGMA) |

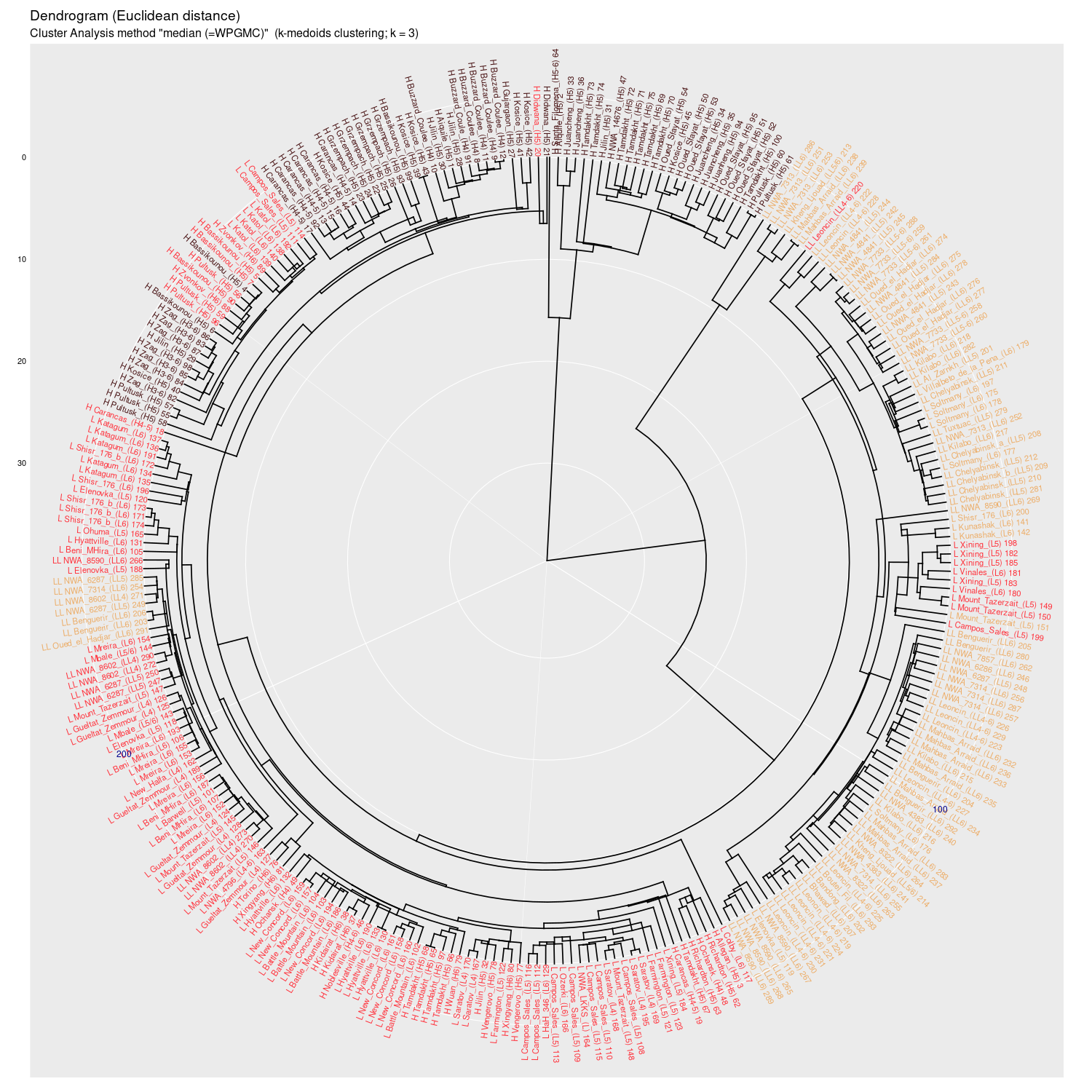
median (WPGMC) |
|

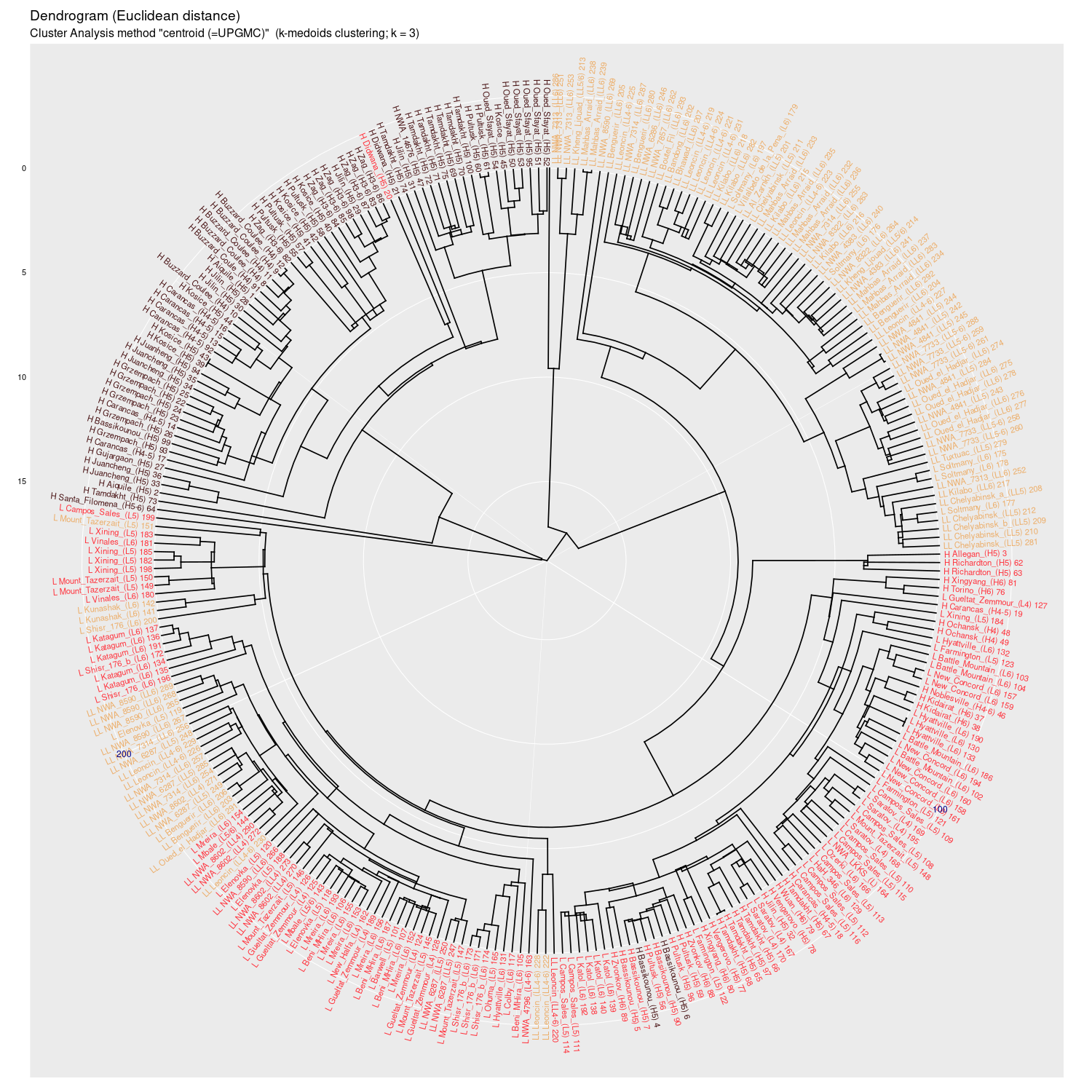
centroid (UPGMC) |
Wykres aglomeracyjny (cluster analysis) na którym widać potencjał
dyskryminacyjny parametrów mössbauerowskich (różne metody aglomeracji)
(wykres sporządzony w pakiecie statystycznym R)
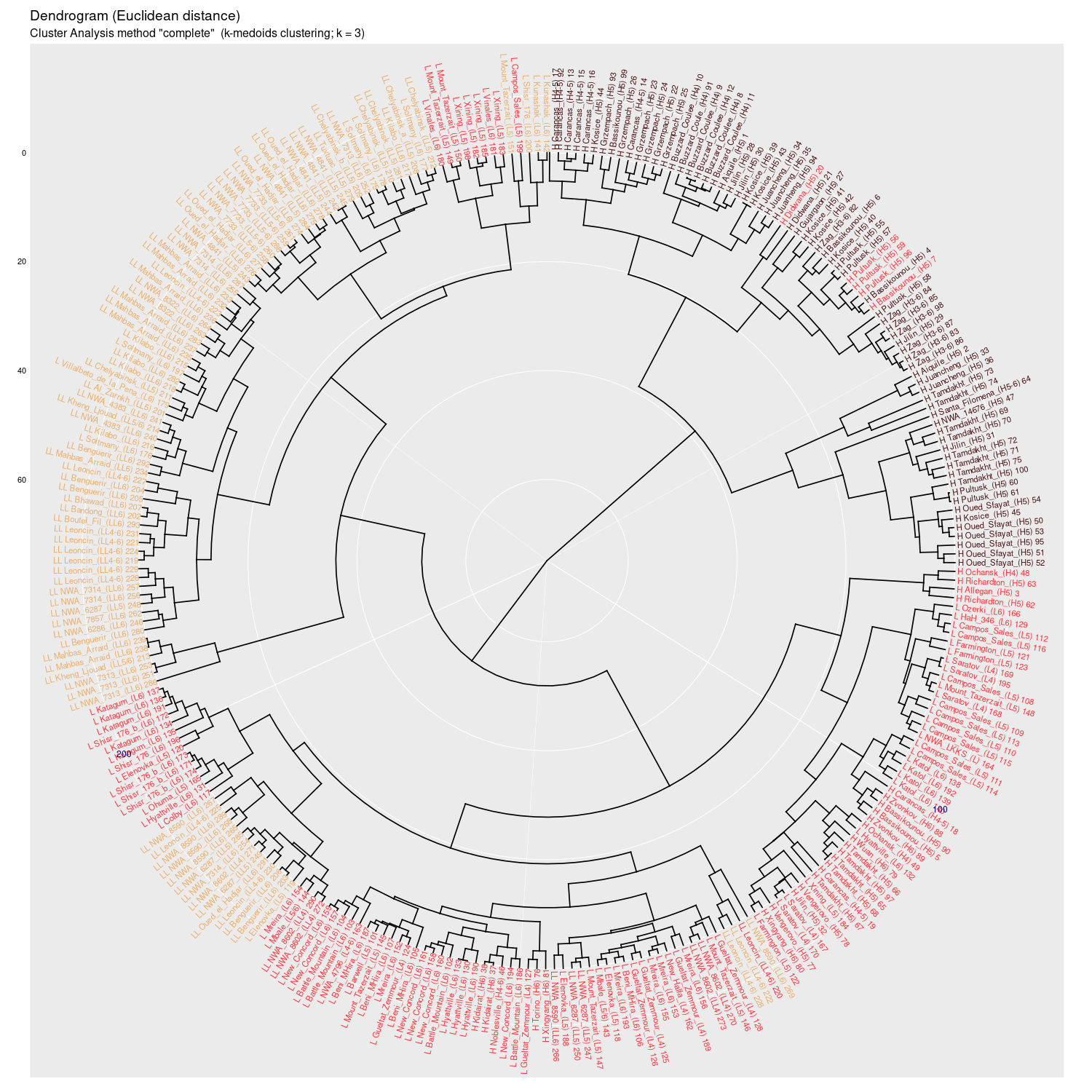
complete |
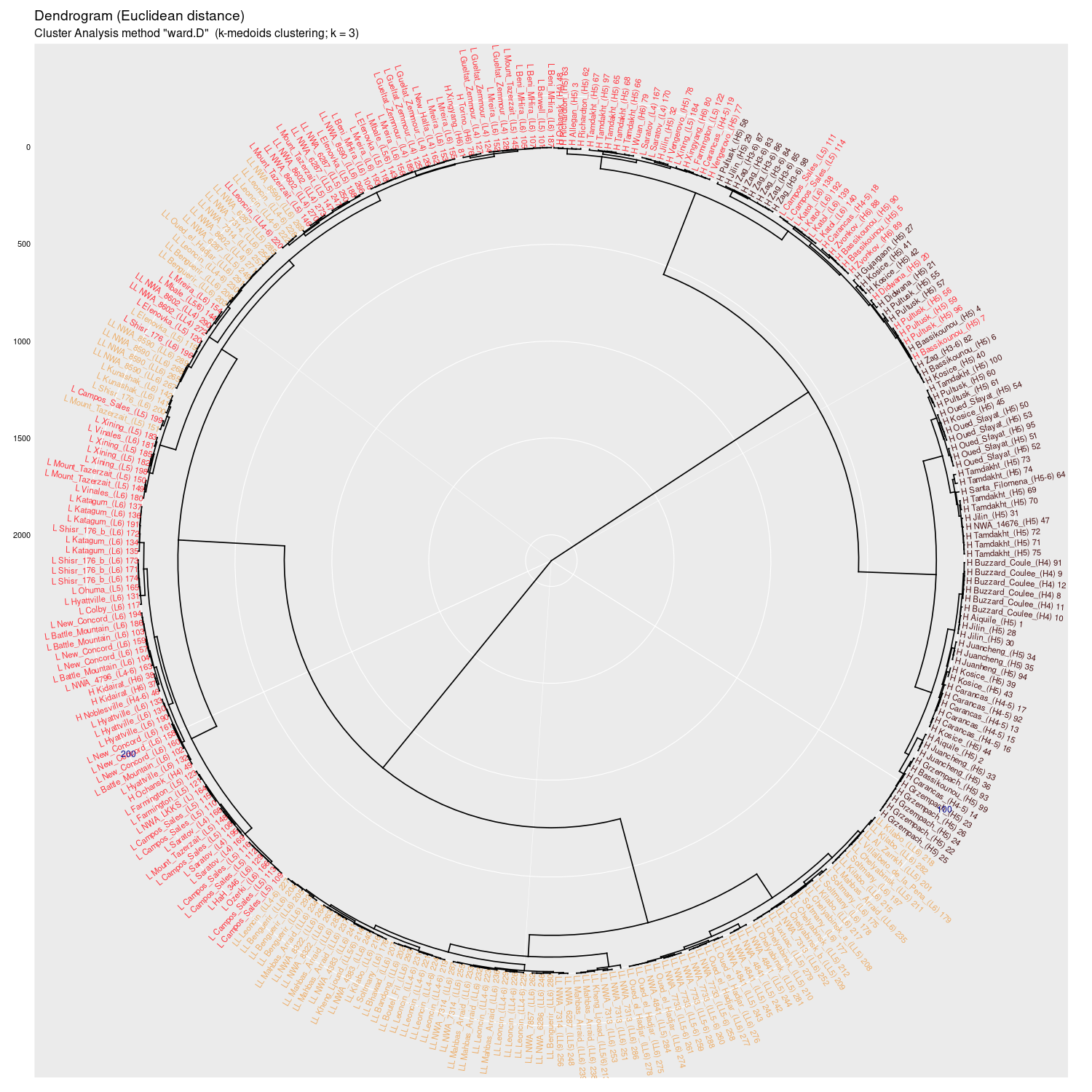
Ward.D |
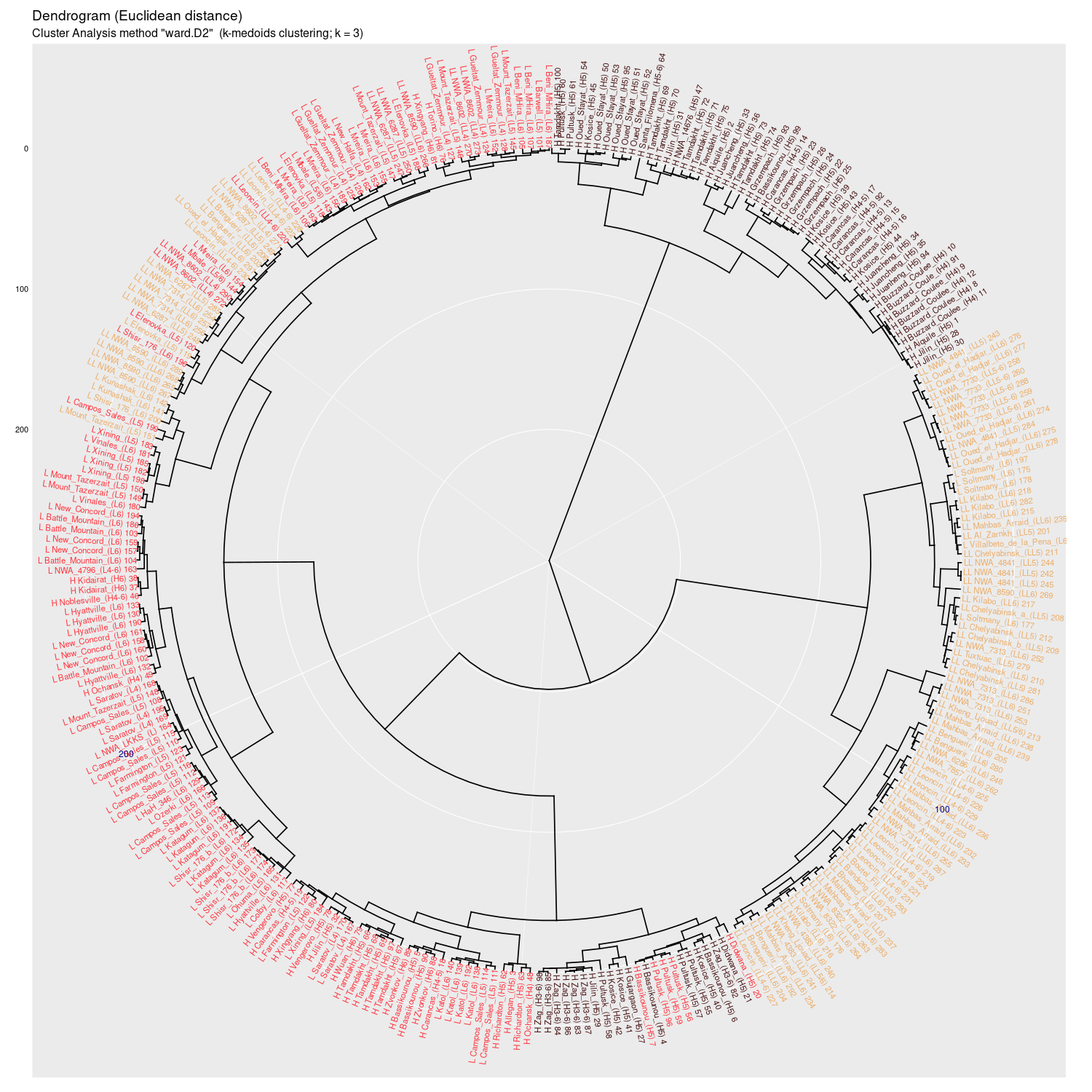
Ward.D2 |
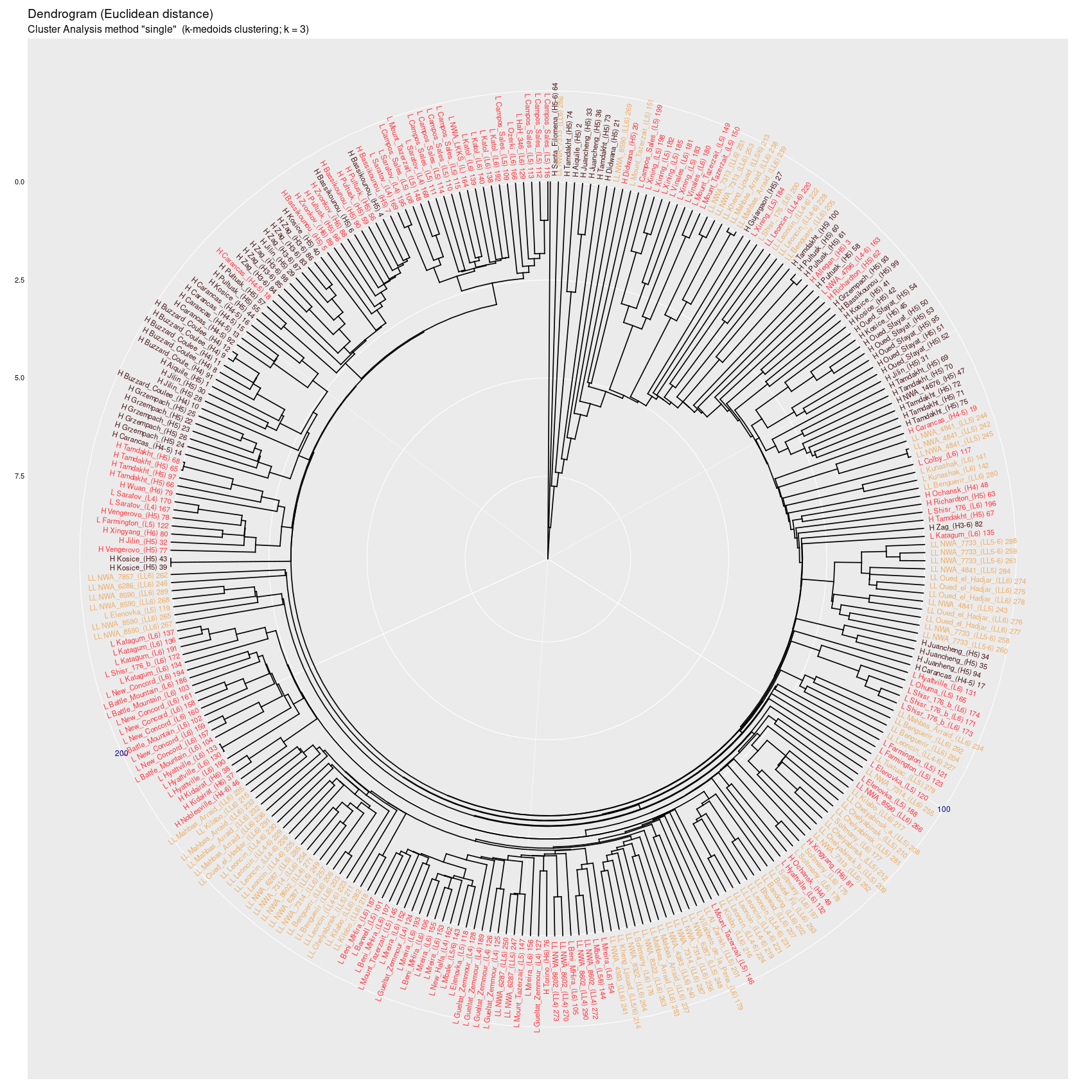
single |
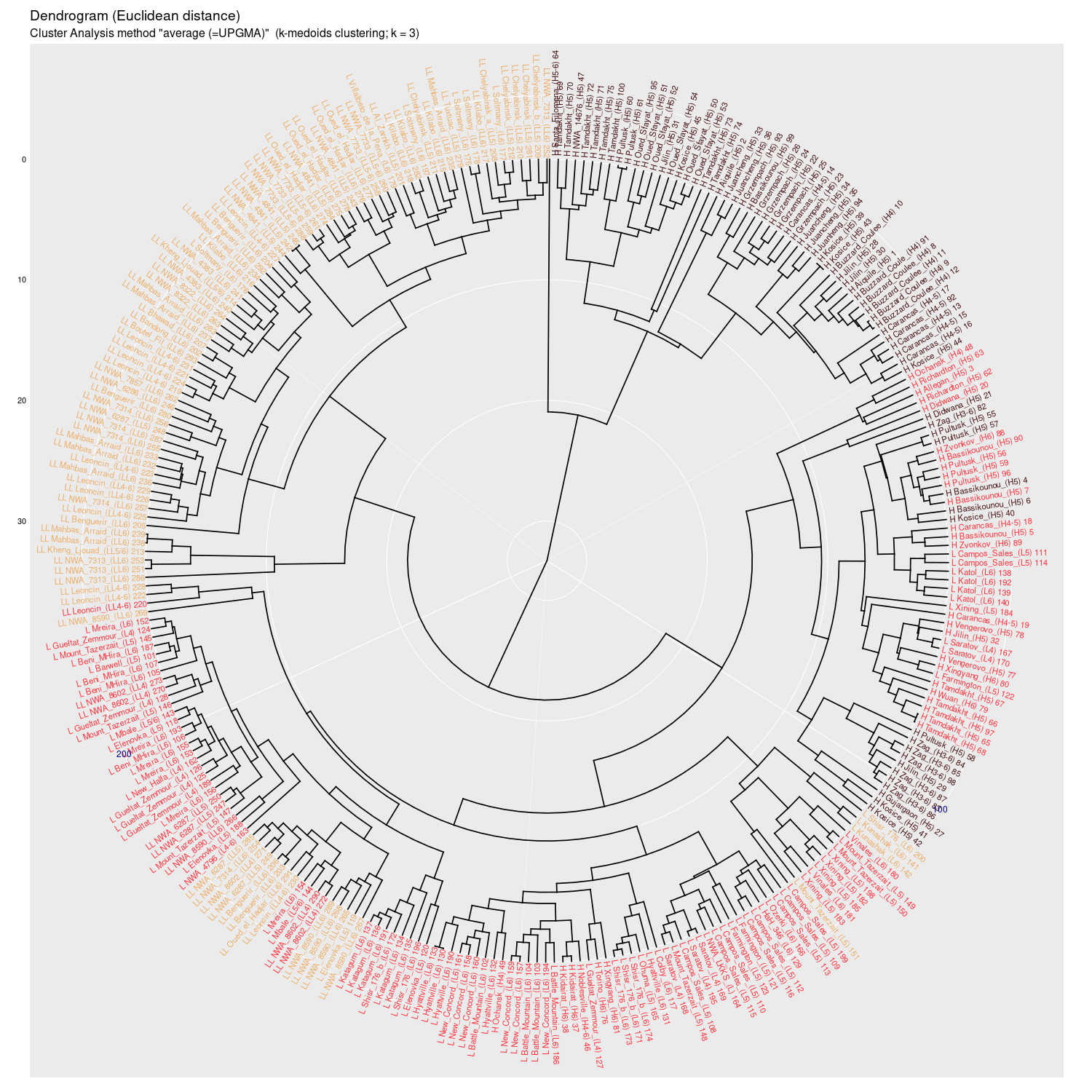
average (UPGMA) |
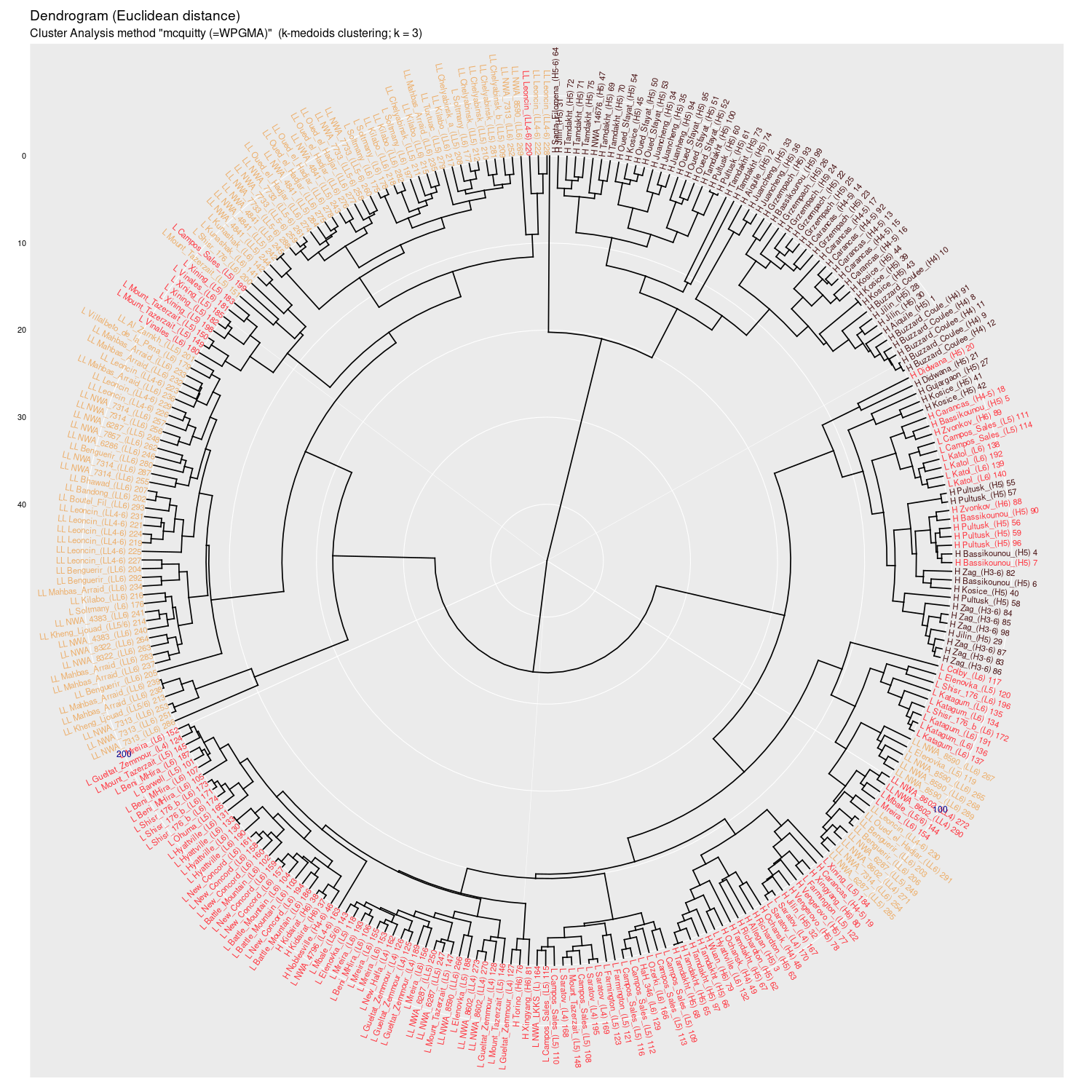
mcquitty (WPGMA) |
median (WPGMC) |
|
centroid (UPGMC) |
Wykres aglomeracyjny (cluster analysis + k-medoids)
Sources
Woźniak Marek, Gałązka-Friedman Jolanta, Duda Przemysław, Jakubowska Martyna, Rzepecka Patrycja, Karwowski Łukasz, (2019), Application of Mössbauer spectroscopy, multidimensional discriminant analysis, and Mahalanobis distance for classification of equilibrated ordinary chondrites, Meteoritics & Planetary Science, vol. 54(8), 2019, s. 1828-1839. Plik doi; streszczenie.